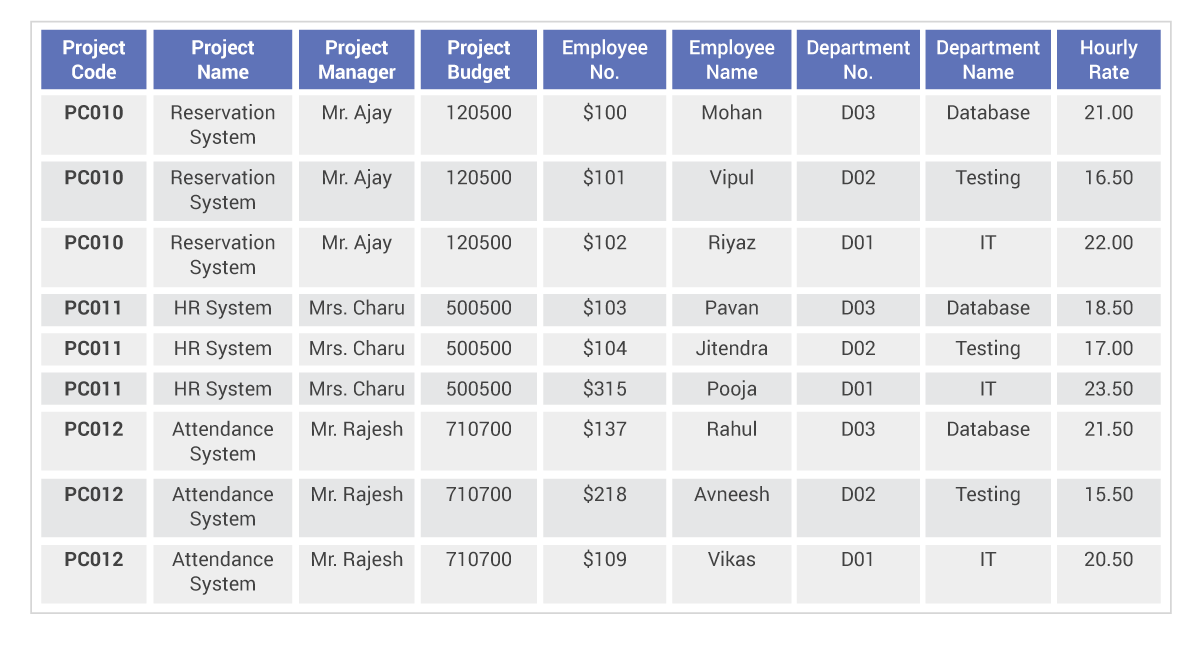
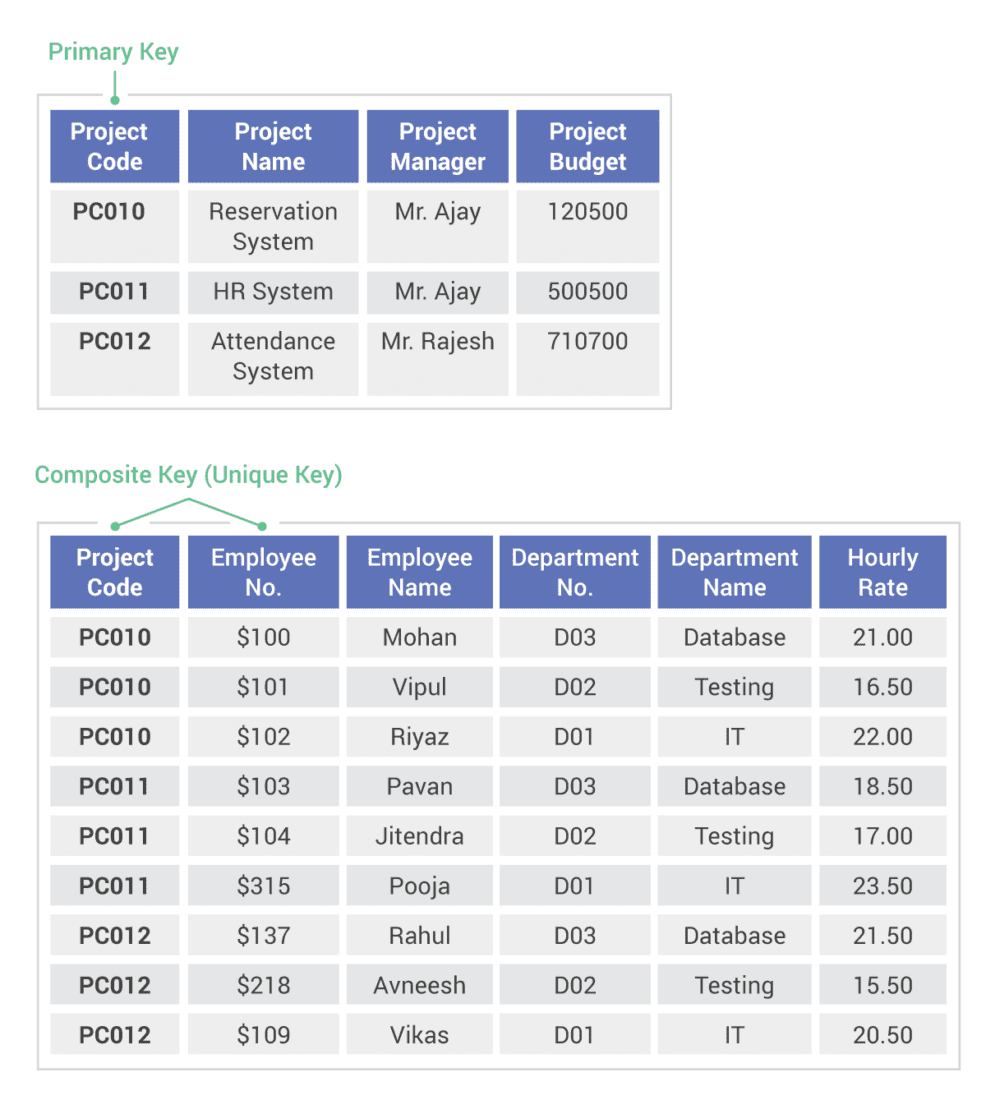
Close-to-the-metal architecture handles millions of OPS with predictable single-digit millisecond latencies.
Learn More- Products
- devHub
- Users
- Resources
- Featured Resource
ScyllaDB University
Level up your skills with our free NoSQL database courses.
Take a CourseCheck out the ScyllaDB Blog
Our blog keeps you up to date with recent news about the ScyllaDB NoSQL database and related technologies, success stories and developer how-tos.
Read More - Resource Center
- Events
- Compare
- Featured Resource
- Pricing
- Contact Us
- Chat Now
- Get Started
- Sign In
- Search
- Button Links
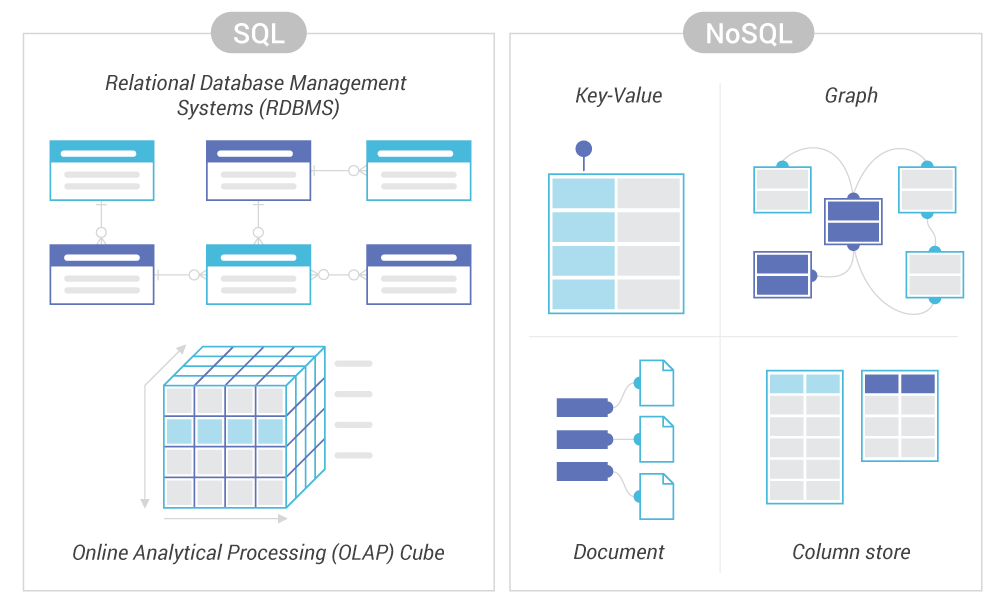
 Looking for extensive training on data modeling for NoSQL Databases? Our experts offer a 3-hour masterclass that assists practitioners wanting to migrate from SQL to NoSQL or advance their understanding of NoSQL data modeling. This free, self-paced class covers techniques and best practices on NoSQL data modeling that will help you steer clear of mistakes that could inconvenience any engineering team.
Looking for extensive training on data modeling for NoSQL Databases? Our experts offer a 3-hour masterclass that assists practitioners wanting to migrate from SQL to NoSQL or advance their understanding of NoSQL data modeling. This free, self-paced class covers techniques and best practices on NoSQL data modeling that will help you steer clear of mistakes that could inconvenience any engineering team.