
The combination of a database and full-text search analytics becomes unavoidable these days. In this blog post, I will demonstrate a simple way to analyze data from a database with analytics software by using ScyllaDB and Elasticsearch together to perform a simple data mining exercise that gathers data from Twitter.
This demonstration will use a series of Docker containers that will run a ScyllaDB and Elasticsearch cluster and a Node.js app that will feed data from Twitter into both platforms. This demo can be run on a laptop or production Docker server. To get started, let’s go over the prerequisites and architecture.
Prerequisites
- Docker installed on a laptop or server with 3GB of RAM or more.
- Twitter API credentials. After signing up for a developer account, go to the Twitter Apps page and click on “Create New App”. The API credentials are provided after the application is created.
- The scylla-code-samples repository from GitHub.
Please note that the prerequisites and configurations for this demo is meant for demonstration purposes only. In production, users should adhere to ScyllaDB’s production environment requirements.
Architecture
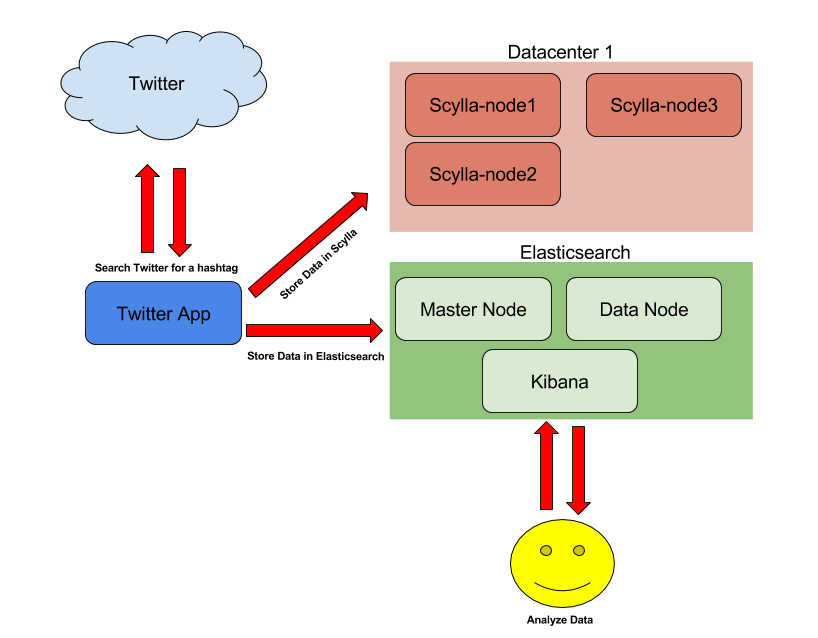
The ScyllaDB architecture in this demonstration consists of three nodes. Nodes 1-2 will be in the first datacenter and the third node will be in the second datacenter. For Elasticsearch, there will be one master node and one data node. The conclude the Elasticsearch architecture, there is a Kibana node that will be used to visually explore the data in Elasticsearch.
The Twitter application is used to connect to the Twitter service and search the live stream for a specific word or hashtag. If a match is found, the Tweet is saved to the ScyllaDB database. The data can be exported from ScyllaDB and into Elasticsearch at any time using the curl command which will be discussed in the proceeding sections of this blog.
Building the Demo
- Clone the scylla-code-samples GitHub repository.
git clone https://github.com/scylladb/scylla-code-samples.git cd scylla-code-samples
- Navigate to the elasticsearch-scylla directory and open the docker-compose.yml with your favorite text editor. Modify the following lines under the Twitter container section:
- consumer_key= - consumer_secret= - access_token_key= - access_token_secret= - twitter_topic=docker
The first four lines should be replaced with your Twitter developer keys from the Twitter Development page. For twitter_topic, change this to any word or hashtag that you want to search for.
- Run the following command to build and run all of the Docker containers
docker-compose up -d
This process may take a long period of time to complete when run for the first time because there are many containers to build.
- Now I will make sure that all of the containers are running. You should see an output similar to this:
Using the demo
- To see the activity from the Twitter application, run the following command:
docker logs -f elasticsearchscylla_twitter_1
I recommend running this command in a separate terminal for this demonstration because it will tail the container’s log to show important activity throughout the demo. After the application starts, it will wait 60 seconds for all of the ScyllaDB and Elasticsearch nodes to come up and then create the Keyspace and table in ScyllaDB and data mappings in Elasticsearch. When those operations are complete, it will begin searching Twitter and writing data to ScyllaDB.
- To count the number of Tweets stored in ScyllaDB, connect to the ScyllaDB node’s container and query the database to see how many Tweets have been recorded.
I can see now that I have one Tweet recorded but this will not look too good when visualizing it next with Kibana. Before proceeding to the next section, it would be best to wait for more records to be written to ScyllaDB.
- Once a decent amount of Tweets are stored in ScyllaDB, run the following command to stop writing Tweets to ScyllaDB.
curl http://127.0.0.1:8080/stop
If you want to continue writing data to ScyllaDB in the future, simply change stop to start in the previous command.
- Transfer the data from ScyllaDB to Elasticsearch.
curl http://127.0.0.1:8080/dump
When this command is run, any existing data in Elasticsearch is deleted. This helps ensure that data is consistent in Elasticsearch from ScyllaDB. When the data transfer is finished, the logs for the Twitter application will say “Data dump complete”.
Visualizing the data with Kibana
Now that there is a little bit of data in Elasticsearch, I can use the Kibana web interface to visualize the data and create charts.
- Access Kibana with a web browser at http://127.0.0.1:5601. When Kibana is loaded for the first time, it will prompt the user to configure an index pattern. Since one is created already from the Twitter app, simply change the default value to “logstash” and click create.


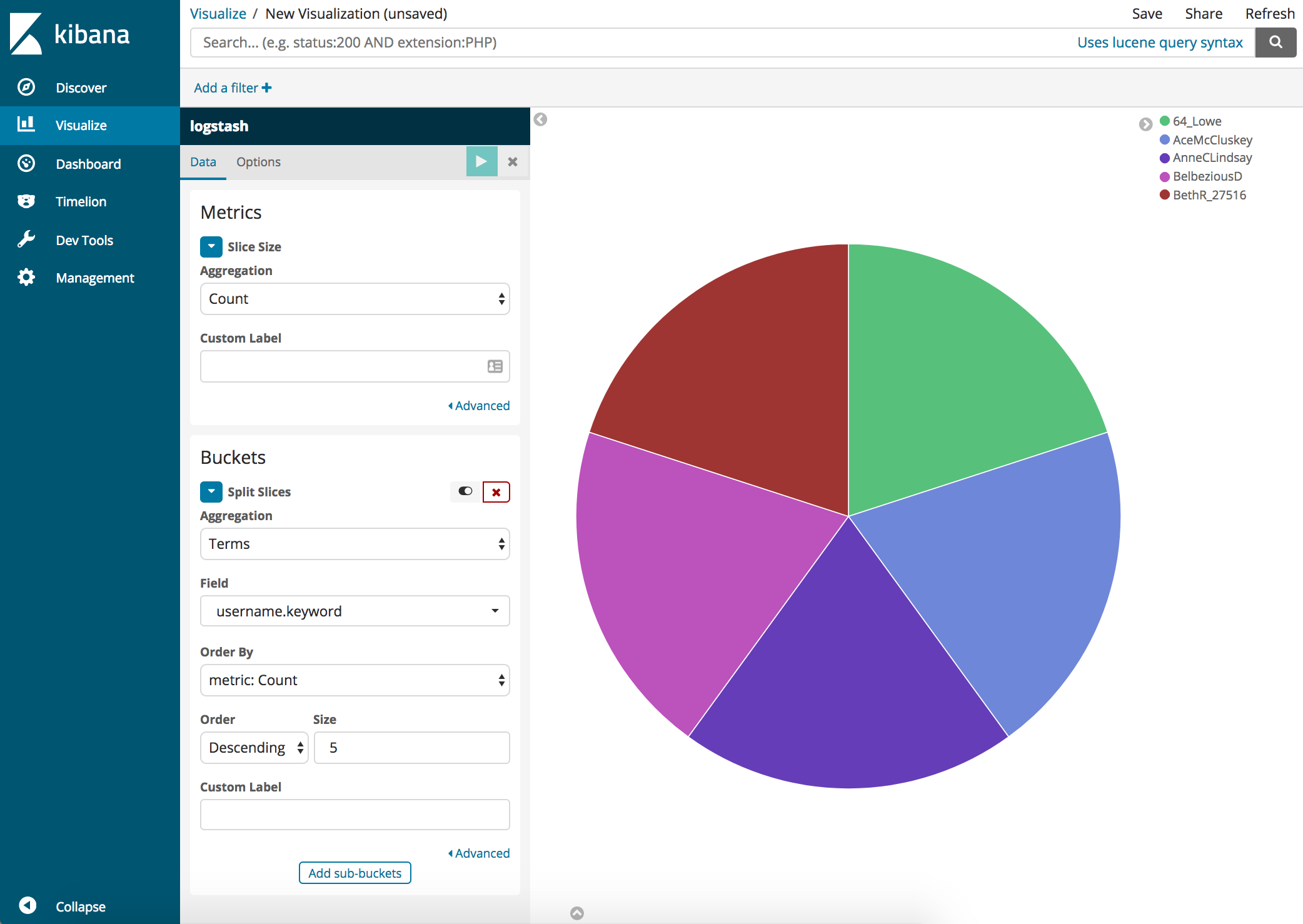
- Let’s visualize the data that was gathered and create a Pie chart that will show who the top Tweeters of the topic chosen are. Click Visualize on the left followed by “Create a visualization”.


- Click on Pie


- Configure the chart as shown and click on the play button.

The pie chart visual is now showing the top Tweeters of the chosen topic.
- To view the actual Twitter data, click on “Discover” and then start reading the data.


Querying data directly from Elasticsearch
While Kibana is a great tool to run queries and visualize data from a web interface, many developers will want to write applications that can communicate directly with Elasticsearch via their API. Since I set the twitter_topic to “scylla” in docker-compose.yml and begun mining data, let’s explore how to perform a simple search query using curl to demonstrate a HTTP request to look for people talking about “ScyllaDB Release”.
The output above displays all of the records that match the term “ScyllaDB Release” and will display all of the characteristics for the Tweet such as who tweeted about it and when.
Conclusion
I hope that you found this data mining tutorial with ScyllaDB and Elasticsearch useful. This demo provides an easy way to try both solutions with barely any effort. Elasticsearch and Kibana are powerful tools that help organizations visualize their data. When combined with ScyllaDB, they will have a complete and easy-to-use solution with optimal performance for their data and analytics needs.



