Last week we announced the release of ScyllaDB Manager 1.2, a management system that automates maintenance tasks on a ScyllaDB cluster. This release provides enhanced repair features that make it easier to configure repairs on a cluster. In this blog, we take a closer look at what’s new.
Efficient Repair
ScyllaDB Manager provides a robust suite of tools aligned with ScyllaDB’s shard-per-core architecture for the easy and efficient management of ScyllaDB clusters. Clusters are repaired shard-by-shard, ensuring that each database shard performs exactly one repair task at a time. This gives the best repair parallelism on a node, shortens the overall repair time, and does not introduce unnecessary load.
General Changes
In order to simplify configuration of ScyllaDB Manager we have removed the somewhat confusing “repair unit” concept. This concept served only as a static bridge between what to do (“tasks”), and when to run them, and was thus unnecessary. A task is defined as the set of hosts, datacenters, keyspaces and tables on which to perform repairs. Essentially it boils down to what you want to repair. Which tasks it operates on exactly is determined at runtime. This means that if you add a new table that matches a task definition filter it will also be repaired by that task even though it did not exist at the time the task was added. This makes ScyllaDB Manager simultaneously easier for users while making the ScyllaDB Manager code simpler, which will also allow us to develop new features faster.
Multi-DC Repairs
One of the most sought-after features is to isolate repairs. ScyllaDB Manager 1.2 provides a simple yet powerful way to select a specific datacenter or even limit which nodes, specific table, keyspace, or even token ranges are repaired.
You can furthermore decide with great precision when to perform repairs using timestamps and time deltas. For example, to repair all the shopping cart related tables in the Asian datacenter and to start the repair task in two hours, you would run a repair command such as this:
sctool repair -c 'cname' --dc 'dc_asia' --keyspace 'shopping.cart_\*' -s now+2h
This command issues repair instructions only to the nodes located in the datacenter dc_asia and repair only the tables matching the glob expression shopping.cart_*. This is a one time repair. To make it recurrent, use the --interval-days flag to specify the number of days between repair tasks. If you want to repair multiple keyspaces at a time, simply add another glob pattern in the --keyspace argument such as this:
sctool repair -c 'name' --dc 'dc_asia' --keyspace 'shopping.cart_\*,audit.\*' -s now+2h
This repairs all the tables in the audit keyspace as well in the same repair task. If you want to skip repairing one of the tables (audit.old, for example) just add the exclude command like this:
sctool repair -c 'name' --dc 'dc_asia' --keyspace 'shopping.cart_*,audit.\*,\!audit.old' -s now+2h
This repairs all tables in the “audit” keyspace except for the table named “old”.
If you want to further control what the repair should use as its source of truth, you can use the --with-hosts flag which specifies a list of hosts. This will instruct ScyllaDB to use only these hosts when repairing, rather than all of them which is normally the case. To repair just a single host you can use the flag --host which is particularly useful in combination with --with-hosts since you can with minimal impact quickly repair a broken node.
By default ScyllaDB Manager will instruct ScyllaDB to repair “primary token ranges” which means that only token ranges owned by the node will be repaired. To change this behavior you can inverse it by simply adding the argument --npr or use --all to repair all token ranges.
A note on glob patterns…
We chose to use glob patterns, for example keyspace.prefix*, for specifying filters as they provide a high degree of power and flexibility without the complexity of regular expressions which can easily lead to human errors. These patterns easily allow you to specify several keyspaces and tables without writing out all of them in a list which can be quite tedious in a large application with lots of different data types.
Simplified Installation
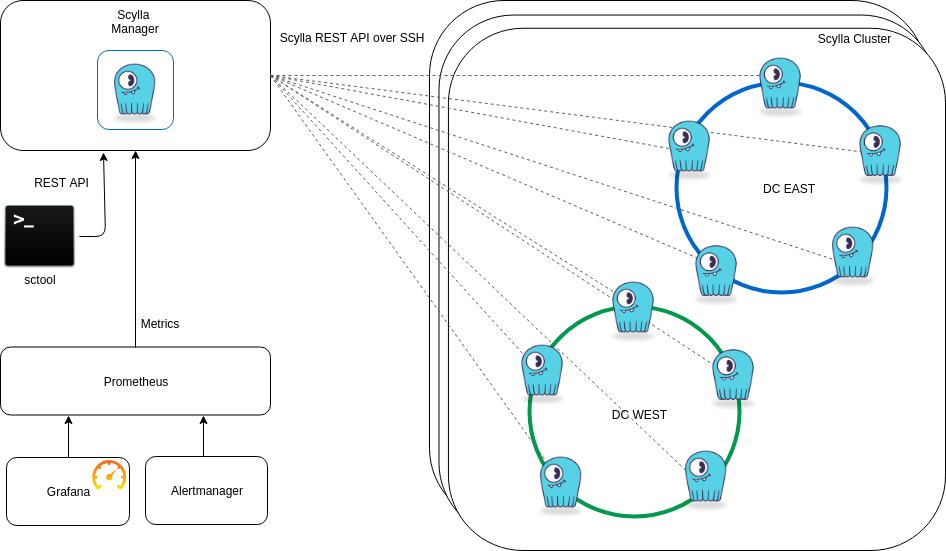
ScyllaDB Manager uses the ScyllaDB REST API for all of its operations. ScyllaDB Manager supports SSH tunneling for its interactions with the ScyllaDB database nodes for increased security. It is not mandatory to do so, but we recommend using SSH tunneling because it does not require any changes to database configuration, and be implemented with a dedicated low-permission user. It also does not need any special software installed on the database machines. This simplifies operations since there is nothing extra to monitor, update, and otherwise manage. The concept of having a companion application installed together with another main application is known as a “sidecar.” We do not believe sidecars to be a good design pattern for ScyllaDB Manager, since this bring additional operational burdens.
In ScyllaDB Manager 1.2, we have made it very easy to setup the SSH connectivity for the ScyllaDB Manager to talk to the ScyllaDB database nodes.
One thing many users reported as being troublesome was the generation and distribution of the SSH keys necessary for this to work. To solve this problem , we have now added the scyllamgr_ssh_setup script that is available after you install ScyllaDB Manager. This script does not simply copy key files, but discovers all the nodes in a cluster for every node sets up the proper user that is needed for the SSH connectivity to work.
To run the script, make sure there is an admin user who has root privileges so that the script can use these permissions to perform the setup. This power user is not remembered or reused in any way but is simply used to perform the needed administrative functions to setup the required user and keys. The admin user is much like the Amazon ec2-user. The script creates a user specified by the -m parameter that the ScyllaDB Manager later uses for its SSH connection. This is a very restricted user as you cannot get shell access.
Generating and distributing the needed keys is as simple as:
scyllamgr_ssh_setup -u ec2-user -i /tmp/amazon_key.pem -m scylla-manager -o /tmp/scyllamgr_cluster.pem -d <SCYLLA_IP>
This generates or reuses the file: /tmp/scyllamgr_cluster.pem which is distributed to all of the nodes in the cluster. In order to do this, the script uses the ScyllaDB REST API to discover the other members of the cluster and sets up the needed users and keys on these nodes as well. If you later add a node to the cluster, you can re-run the script for just that node.
Further improvements
- HTTPS – By default, the ScyllaDB Manager server API is now deployed using HTTPS for additional safety. The default port is 56443 but this can be changed in the config file /etc/scylla-manager/scylla-manager.yaml.
- The SSH config is now set per cluster in the
cluster addcommand. This allows a very secure setup where different clusters have their own keys. - The ssh configuration is now dropped and and any data available will be migrated as part of the upgrade.
cluster addis now topology aware in the sense that it will discover the cluster nodes if you just supply one node using the--hostargument. There is no need to specify all the cluster nodes when registering a new cluster.repairwill obtain the number of shards for the cluster nodes dynamically when it runs so you do not need to know the shard count when you add the cluster. This can be very convenient in a cluster with different sized nodes.- Automated DC selection – ScyllaDB Manager will ping the nodes and determine which DC is the closest and then use that for its interactions with the cluster whenever possible. The
repair_auto_scheduletask has been replaced by a standard repair task like any other that you might add. - The visual layout of the progress reporting in sctool is greatly improved.