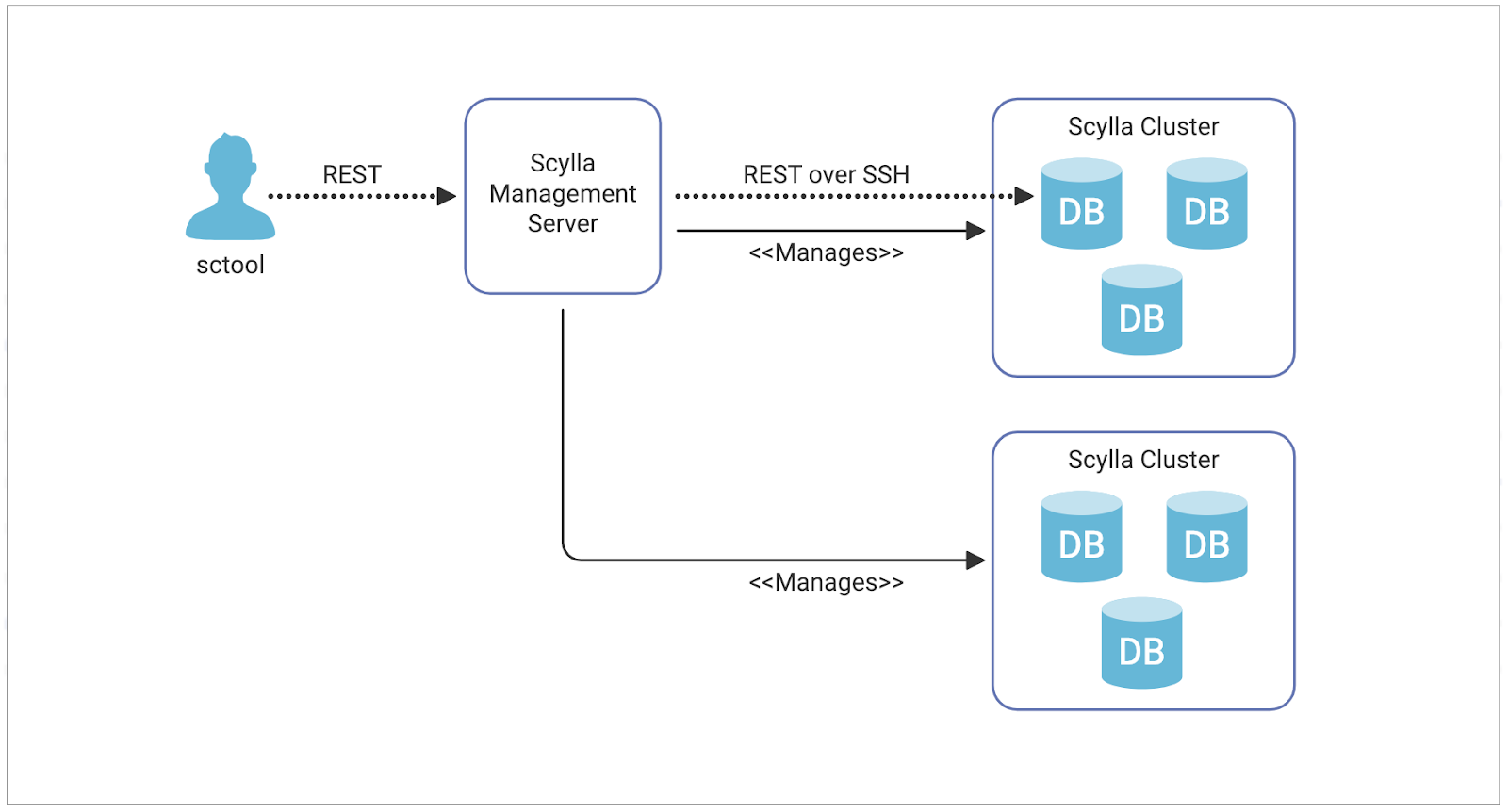
The ScyllaDB Manager team is pleased to announce the release of ScyllaDB Manager 2.1, a production-ready version of ScyllaDB Manager for ScyllaDB Enterprise and ScyllaDB Open-Source customers. ScyllaDB Manager is a centralized cluster administration and recurrent tasks automation tool. Manager 2.1 brings improvements to Backup, Repair and Health Check tasks.
Manager 2.1 is backward compatible with the previous version of ScyllaDB Manager, and in particular, can continue a Manager 2.0 backup plan. The release includes a correlated Manager Agent 2.1 release.
ScyllaDB Enterprise customers are encouraged to upgrade to ScyllaDB Manager 2.1 in coordination with the ScyllaDB support team.
Useful Links:
- Download ScyllaDB Manager and ScyllaDB Manager Agent for ScyllaDB Enterprise customers
- Download ScyllaDB Manager and ScyllaDB Manager Agent for open source users (up to 5 nodes)
- ScyllaDB Manager Docker instance and example
- ScyllaDB Manager 2.1 documentation
- Upgrade from ScyllaDB Manager 2.0 to ScyllaDB Manager 2.1
- Submit a ticket for questions or issues with Manager 2.1 (ScyllaDB Enterprise users)
Backup Improvements
The speed of backup to AWS S3 is improved, by changing the structure of the metadata and improving the read and purge speed of older backups.
- Usability: Add Backup Delete command
- Usability: In addition to data, ScyllaDB Manager will also include backup of the full schema. To enable this feature, one needs to provide CQL credentials by running
sctool cluster updatewith--usernameand--passwordpass. - Robustness: ScyllaDB Manager allows a backup cluster which has down nodes as long as all ring tokens are covered by live nodes.
- Performance: In case of lots of small tables the total upload time is shortened. Manager uses long polling to move to another table immediately when the current table’s data is uploaded.
- Performance: improved pure performance
- Storage: Better disk space management
- Old snapshots are deleted before taking a new one
- Active snapshots are deleted before purge phase
- Performance: Number of bytes sent from Agent to Server when uploading (to check the progress) is reduced to just a few bytes (vs up to 10MB in extreme cases).
- Usability: Sctool backup list command shows the total backup size
- Usability: Sctool backup files command can now work even when the number of tables or files in the backup is huge.
- Usability: Config option
poll_intervalis removed.
Healthcheck Improvements
Manager Health Check task is improved by making it more reliable, and removing cases of false alerts.
- Robustness: CQL ping from ScyllaDB Manager can now execute a
CQL SELECTquery, instead ofCQL OPTIONin Manager 2.1. This gives a more reliable latency and status reports.
To enable this option, one needs to provide CQL credentials by running sctool cluster update--usernameuser--passwordpass - Robustness: Nodes that are known to be in Down state are not pinged (REST and CQL), eliminating false alerts.
- Usability: Sctool status command is enhanced to:
- Shows all clusters by default
- has new statuses
UNAUTHORISEDandTIMEOUTand shows HTTP error code in case of REST check failure - Provides information from gossip in nodetool format ex, UN, DN, UJ
- SSL column is removed; we add SSL to CQL output
Repair Improvements
A more granular control of the repair operation gives more control on repair speed.
- Usability: School repair command gained
--intensityflag that lets you control repair speed. - Usability: resuming a repair will always work regardless of the repair age. This can be overridden using the `
max_age` configuration.
Other Improvements
- Agent binary can take multiple config files (needed for docker)
- Config files are better validated, values in config files that are not recognised as options will trigger errors.
- Rclone base is changed from v1.50.2 to v1.51.0.
- Go version upgrade from 1.13.5 to 1.13.8
- Debug (pprof) port enabled by default, bound to localhost – from both Manager server and agent.
- Logging of errors is improved, there is no errorVerbose just error message. For errors logged in the ERROR level we added errorStack that contains a stack trace of the error.
- Manager Server and Agent transport: retry backoff improvements
- In some cases (ex. when body was read) we did not retry – this is fixed
- For requests originating from sctool / rest API we use a different retry policy when request has to be performed against a given host (1 retry wait 1s).
- Sctool
--show-tableflag takes no parameter - Sctool tables header start with capital letters
Monitoring
You can use ScyllaDB Monitoring Stack 3.3 with -M 2.1 option to get Manager 2.1 dashboards
The following metric was removed in Manager 2.1:
scylla_manager_backup_move_manifest_retries