
ScyllaDB Cloud now offers a new ScyllaDB Cloud Calculator to help you estimate your costs based on your database needs. While it looks like a simple tool, anyone steeped in the art of database capacity planning knows that there is often far more to it than meets the eye. In this blog post we’ll show you how to use our handy new tool and then illustrate it with an example from a fictional company.
Considerations for the Cloud
One of the great things about using the cloud is that capacity planning mistakes can be cheaper: It is treated as an expense, adjustable monthly, and has no impact on your annual capital budget. You’re not on the hook for equipment costs if you’ve underspecified or overspecified a system. Even if you get it wrong it’s relatively easy to change your capacity later. In many cases people don’t bother with precise capacity planning anymore, settling on rough estimates. For many situations, e.g., stateless applications, this is fine. Experimentation is certainly a good way to find the right capacity.
Yet in the case of stateful systems like databases capacity planning is still vital. Because although modern databases are elastic — allowing you to add and remove capacity — this elasticity is limited. For example, databases may need hours to adjust, making them unable to meet real-time burst traffic scaling requirements. Scaling a database is relatively slow and sometimes capped by the data model (e.g. partitioning) or data distribution methods (replication).
As well, many databases are made more affordable by signing longer term committed license agreements, such as annual contracts. In such cases, you want to make sure you are signing up for the actual capacity you need, and not overprovisioning (wasting your budget on excess capacity) or underprovisioning (risking hitting upper bounds on performance and storage capacity).
Using the ScyllaDB Cloud Calculator
Now let’s get into the ScyllaDB Cloud Calculator itself and see how it works. While some experienced hands may already know exactly what instance types they want and need — by the way, we still show you prices by instance types — others may only have a general idea of their requirements: throughput in reads or writes, or total unique data stored. In this latter case, you want ScyllaDB Cloud to instead take in your requirements, recommend to you how many and what specific types of servers you will need to provision, and inform you of what that will cost based upon on-demand or 1-year reserved provisioning.
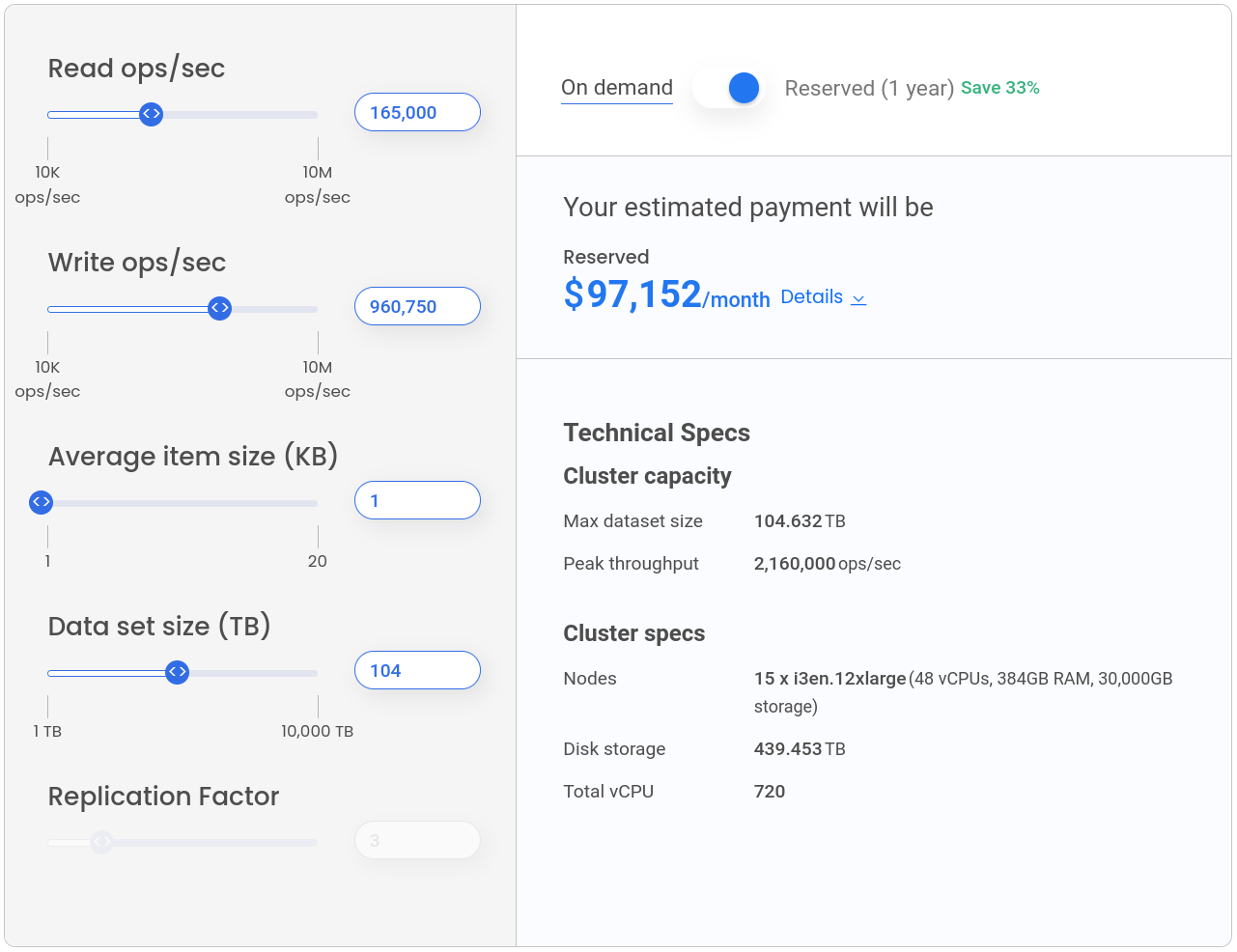
We have written a separate guide for how to use the ScyllaDB Cloud Calculator, but let’s go through some of the basics here. With our calculator, you can specify the following attributes:
- Read ops/sec
- Write ops/sec
- Average item size (in KB)
- Data set size (in TB)
- On demand or reserved (1 year)
See How ScyllaDB Cloud Compares
You can also use the ScyllaDB Cloud Calculator to compare ScyllaDB Cloud pricing to the following NoSQL databases:
- Amazon DynamoDB
- DataStax Astra
- Amazon Keyspaces
Note that while many features across these databases may be the same or similar, there will be instances where specific features are not available, or there may be similar features that vary widely in implementation across the different offerings. How ScyllaDB refers to “Reserved” and “On-Demand” resources also may differ from how other vendors use these same terms. You are encouraged to contact us to find out more about your specific needs.
ScyllaDB will strive to maintain current pricing on these competitors in our calculator. Yet if you find any discrepancy between our calculator and what you find on a competitor’s website, please let us know.
Assumptions and Limitations
The pricing calculator today cannot take into account all the factors that can modify your capacity, production experience and costs. For example, the calculator does not model the CPU or IO requirements of, say, Materialized Views, Lightweight Transactions, highly variable payload sizes, or frequent full table or range scans. Nor can it specifically model behavior when you apply ScyllaDB Cloud’s advanced features such as Workload Prioritization, where different classes of reads or writes may have different priorities. Further, note the pricing calculator by default sets the Replication Factor for the cluster to 3.
If you have a need to do more advanced sizing calculation, to model configurations and settings more tailored to your use case, or to conduct a proof-of-concept and your own benchmarking, please reach out and contact our sales and solutions teams directly.
For now, let’s give an example of a typical use case that the calculator can more readily handle.
Example Use Case: BriefBot.ai
Welcome to BriefBot.ai, a fictional service that is growing and about to launch its second generation infrastructure. The service creates and serves personalized briefs from a variety of data sources based on user preferences. Users will scroll through their feeds, seeing briefs in some order (we call it a “timestamp” but it can be virtual time to support algorithmic feed) from different bots. Briefs also have points, which are awarded by users and are used to enhance the ML algorithms powering the service. This service is expected to become very popular and we project it will have tens of millions of users. To support this scale, we have decided to use ScyllaDB as the main datastore for storing and serving users’ feeds.
Each feed is limited to 1,000 daily items — we really don’t expect users to read more in a single day, and each item is about 1kb. Further, for the same of data retention, the scrollback in the feed is limited. Historical data will be served from some other lower priority storage that may have higher latencies than ScyllaDB. A method such as Time To Live (TTL) can evict older data records. This also governs how swiftly the system will need to grow its storage over time.
Data Model
CREATE KEYSPACE briefbot WITH REPLICATION = {'class': 'SimpleStrategy', 'replication_factor': 3}
CREATE TABLE briefs (
user_id UUID,
brief_id UUID,
bot_id UUID,
timestamp TIMESTAMP,
brief TEXT,
points int,
origin_time TIMESTAMP,
PRIMARY KEY (user_id, timestamp)
)The briefs table is naturally partitioned by user_id and has everything we need when loading the feed, so we only need to do one query when a user is looking at the feed
SELECT * FROM briefs WHERE user_id=UUID AND timestamp<CURRENT_POSITION PER PARTITION LIMIT 100
This is a common pattern in NoSQL: denormalizing data such that we can read it with a single query. Elsewhere we will have another database containing briefs accessible by bot id, brief id etc, but this database is specifically optimized for fast feed loading experience of our users’ feeds. For example, if we need bot logos we might add another field “bot_avatar” to our table (right now we’ll fetch bot avatars from a CDN, so this isn’t important). Also note that in our example data model we specified using SimpleStrategy to keep things simple; we advise you choose NetworkTopologyStrategy for an actual production deployment.
While this table is being read synchronously, writes are done by a processing pipeline asynchronously. Every time a bot generates a new brief, the pipeline writes new brief items to all relevant users. Yes, we are writing the same data multiple times — this is the price of denormalization. Users don’t observe this and writes are controlled by us, so we can delay them if needed. We do need another subscriptions table which tells us which user is subscribed to which bot:
CREATE TABLE subscriptions (
user_id UUID,
bot_id UUID,
PRIMARY KEY (bot_id)
)Notice the primary key of this table is bot_id, you might wonder how we are able to handle bots which may have millions of users subscribed to them. In a real system this would also cause a large cascade of updates when a popular bot has a new brief – the common solution for this problem would be to separate the popular bots to a separate auxiliary system which has briefs indexed by bot_id and have users pull from it in real time. Instead we will make bot_id a virtual identifier, with many uuids mapped to the same bot; every “virtual bot” will only have several thousand users subscribed to it.
Workload Estimation
Now that we have a rough design and data model, we can start estimating the workload. Our product manager has also provided some estimates on the expected user base and growth of the service, which we can feed into a guesstimation tool.
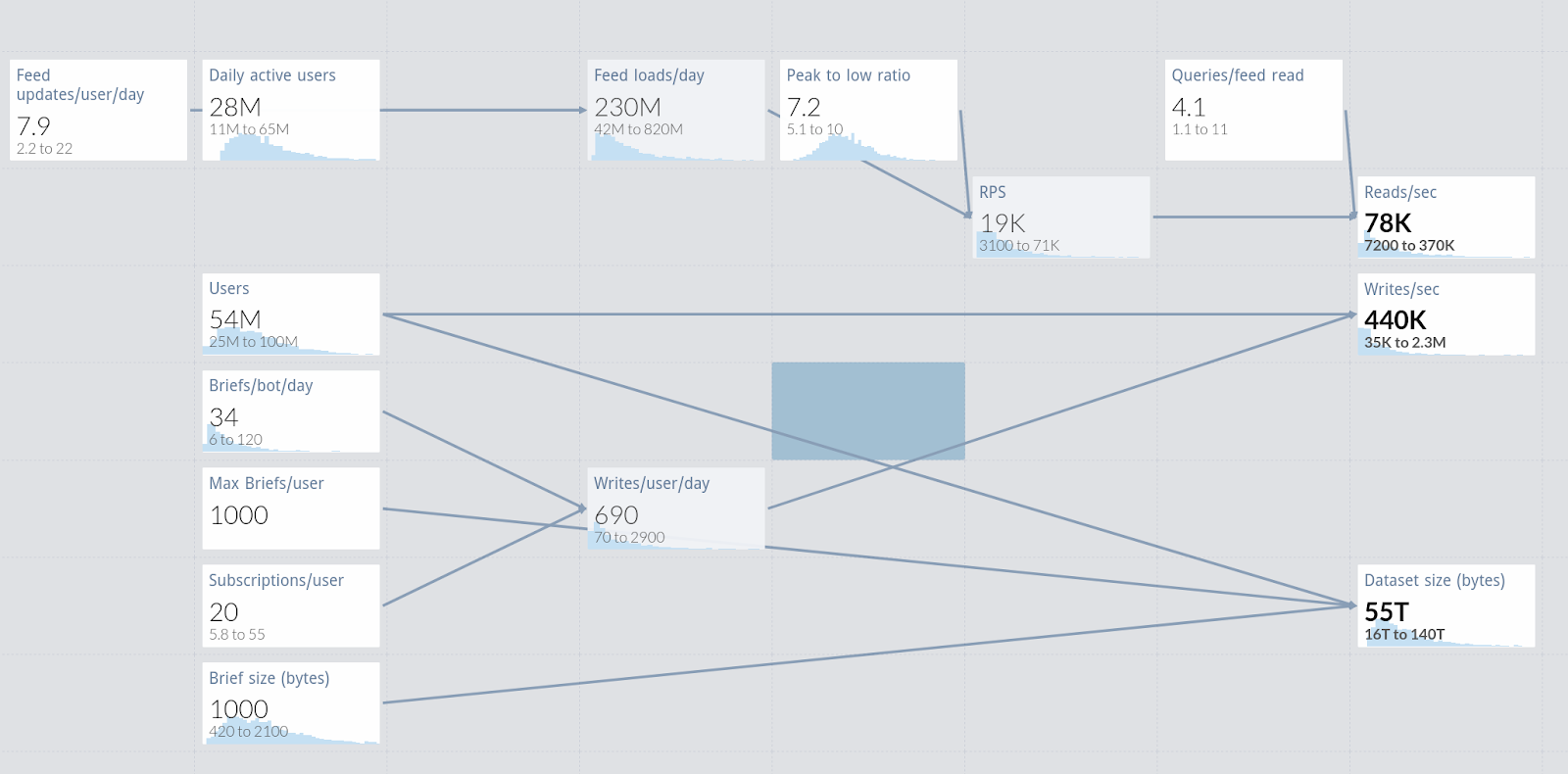
Our initial guesses for the number of users are given as ranges based on market research. The model is based on data both from known sources (e.g. the number of briefs per bot which we control) and unknown sources outside of our control (e.g. the number of users and their activity). The assumptions we make need to take into account our uncertainty, and thus larger ranges are given to parameters we are less sure of. We can also use different distributions for different parameters, as some things have known distributions. The output of the model is also given as distributions, and for sizing our system we will take an upper percentile of the load — 90th percentile in our case. For systems that cannot be easily scaled after initial launch we would select a higher percentile to reduce the chances of error – but this will make our system substantially more expensive. In our example, the values for database load are:
| P50 | P90 | P95 | |
| Reads/sec | 41,500 | 165,000 | 257,000 |
| Writes/sec | 195,000 | 960,750 | 1,568,000 |
| Dataset (TB) | 44 | 104 | 131 |
As you can see, there is a large difference between the median and the higher percentiles. Such is the cost of uncertainty! But the good news is that we can iteratively improve this model as new information arrives to reduce this expensive margin of error.
Growth over Time
It is unrealistic to assume that the system will serve the maximal load on day one, and we expect gradual growth over the lifetime of the system. There are several models we can use to predict the growth of the system, e.g. linear, logistic or exponential. Those kinds of models are very helpful for an existing system where we have data to extrapolate from. However our system is new; Thankfully ScyllaDB is scalable and allows scaling up and down, so we only need to make sure that we have enough capacity when the system launches; we can adjust the capacity based on real data later on.
Compaction
Compaction affects both the required storage and the required compute power. Different compaction strategies give different performance for reads and writes and for different situations. For this system, we choose the Incremental Compaction Strategy available as part of ScyllaDB Enterprise which powers ScyllaDB Cloud. This compaction strategy accommodates a write heavy scenario while keeping space amplification to a reasonable level. Our calculation of required resources will have to be adjusted for the requirements of compaction, and this is handled by the ScyllaDB Cloud sizing calculator.
Deciding on Operating Margins
One of the important decisions that need to be made when sizing a cluster is how much operating margin we would like to have. Operating margin accounts for resilience, e.g. degraded operation when a node is lost, and also for load fluctuations, maintenance operations and other unforeseen events. The more operating margin we take, the easier it is to operate the cluster, but additional capacity can be expensive. We would like to choose a margin that will cover what is likely to happen, relying on our ability to add nodes in the case of unforeseen events.
The operating margin we choose will account for:
- 1 node failure
- Routine repair cycle
- Peak load increase of 25%
- Shards which are 20% hotter than average shard load
These margins can be either conservative and be stacked on top of another, or optimistic and overlapping. We choose to be optimistic and assume there is a small chance of more than one or two of the above happening simultaneously. We will need to make sure our capacity has a margin of at least one node or 25%, whichever higher. This margin will be applied to the throughput parameters, as storage already has its own margin for compaction, node failures and such – this is part of the design of ScyllaDB.
Estimating Required Resources Using the ScyllaDB Cloud Calculator
After having an estimate for the workload and operational margins, we still need to calculate the amount of resources needed to handle this workload. This can be quite challenging, as we have discussed in a previous blog post, and requires a performance model of the system. Knowing the required resources, we can use a few thumb rules to derive the required configuration of servers and composition of the cluster. If you are running on EC2, the calculator already recommends a cluster composition of EC2 instances, currently i3 and i3en instance types only.
Again, the calculator is just an estimate — the exact performance of a complex system like ScyllaDB depends on the actual data and usage patterns, but it does provide results which are good enough for initial design and cost estimation.
Selecting the Right Cluster
According to the calculator, a cluster of 15 i3en.12xlarge instances will fit our needs. This cluster has more than enough throughput capacity (more than 2 million ops/sec) to cover our operating margins – as the limiting factor in this case was storage capacity. But why did the calculator choose large 12xlarge nodes and not a large number of smaller nodes?
ScyllaDB is a redundant cluster which is resilient to node failures, but that does not mean node failures have zero impact. For instance, in a recent disaster involving Kiwi.com, a fire took out an entire datacenter, resulting in the loss of 10 out of the total 30 nodes in their distributed cluster. While ScyllaDB kept running, load on the other servers did increase significantly. As we have previously discussed we need to account for node failures in our capacity planning.
We should note that using larger nodes may be more efficient from a resource allocation point of view, but it results in a small number of large nodes which means that every failing node takes with it a significant part of cluster capacity. In a large cluster of small nodes each node failure will be less noticeable, but there is a larger chance of node failures — possibly more than one! This has been discussed further in The Math of Reliability.
We have a choice between a small cluster of large machines which emphasizes performance and cost effectiveness in a non-failing state and a large cluster of small machines which is more resilient to failures but also more likely to have some nodes failing. Like all engineering tradeoffs, this depends on the design goals of the system, but as a rule of thumb we recommend a balanced configuration with at least 6-9 nodes in the cluster, even if the cluster can run on 3 very large nodes.
In the case of BriefBot, we will use the calculator recommendation of 15 i3.12xlarge nodes which will give us ample capacity and redundancy for our workload.
Monitoring and Adjusting
Congratulations! We have launched our system. Unfortunately, this doesn’t mean our capacity planning work is done — far from it. We need to keep an eye on the cluster utilization metrics and make sure we are within our operational margin. We can even set some predictive alerts, perhaps using linear regression (available in Graphite and Prometheus) or more advanced models offered by various vendors. Some metrics, like the amount of storage used are fairly stable; others, like utilization, suffer from seasonal fluctuations which may need to be “smoothed” or otherwise accounted for in prediction models. An simple yet surprisingly effective solution is to just take the daily/weekly peaks and run a regression on them — it works well enough in many systems.
In the case of ScyllaDB, the metrics we would like predict growth on would be:
- Storage used
- CPU utilization (ScyllaDB, not O/S)
These metrics and many more are available as part of ScyllaDB Monitoring Stack.
Summary
Capacity planning is an important step in any large scale system design that often requires operational knowledge and experience of the systems involved. With the new sizing calculator we hope to make administrators’ lives easier when planning new clusters. If you are interested in discussing this further, as always we are available on the community Slack channel for questions, comments and suggestions.











