
With the rise of real-time applications reading and writing petabytes of data daily, it’s not surprising that database speed at scale is gaining increased interest. Even if you’re not planning for growth, a surge could occur when you’re least expecting it. Yet scaling latency-sensitive data-intensive applications is not trivial. Teams often learn all too late that the database they originally selected is not up to the task.
Benchmarks performed at petabyte scale can help you understand how a particular database handles the extremely large workloads that your company expects (or at least hopes) to encounter. However, such benchmarks can be challenging to design and execute.
At ScyllaDB, we performed a foundational petabyte benchmark of our high-performance, low-latency database for a number of reasons:
- To help the increasing number of ScyllaDB users and evaluators with petabyte-scale use cases understand if our database is aligned with their requirements for speed at scale.
- To establish a baseline against which to measure the performance improvements achieved with the new series of ScyllaDB V releases and the latest AWS EC2 instances, such as the powerful I4i family.
- To quantify the latency impact of ScyllaDB Enterprise’s unique workload prioritization capability, which allows admins to allocate “shares” of the available hardware infrastructure to different workloads.
GET SCYLLADB CEO DOR LAOR’S PERSPECTIVE ON THE LATEST RELEASE
This blog provides a summary of the results. If you want to drill down deeper, take a look at the related paper that outlines the configuration process, results (with and without workload prioritization), and lessons learned that might benefit others planning their own petabyte-scale benchmark.
A Quick Look at the Petabyte Benchmark Results
ScyllaDB stored a 1 PB data set using only 20 large machines running two side-by-side mixed workloads at 7.5 million operations per second and single-digit millisecond latency.
The results reflect a storage density of 50 TB/server, which is unparalleled in the industry. The amount of servers contributes to a low total cost of ownership (TCO) as well as operational simplicity.
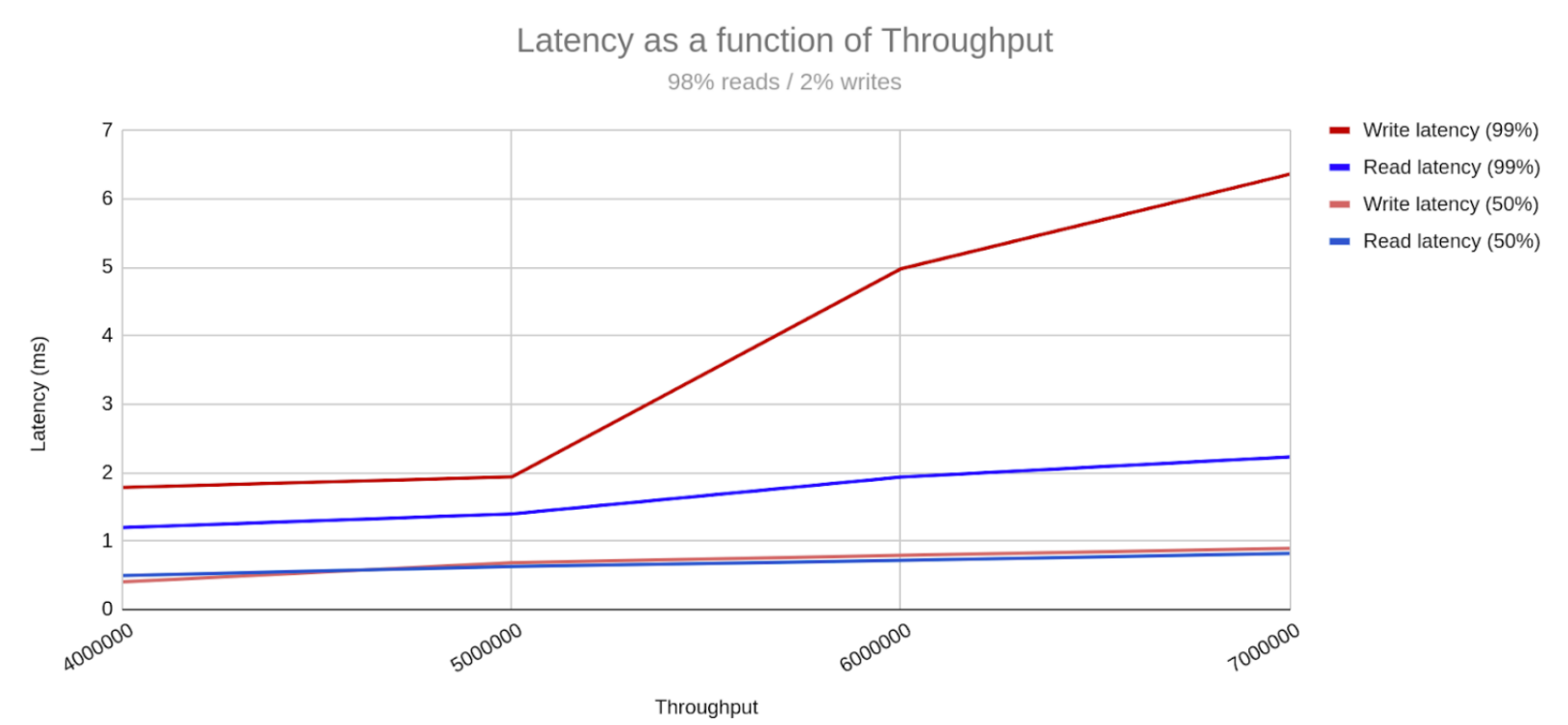
The ScyllaDB cluster achieved single-digit millisecond P99 latency with 7M TPS
In this benchmark, ScyllaDB demonstrated workload prioritization — one of its unique features that allows users to assign priorities per workload. Workload prioritization enables cluster consolidation and offers an additional level of savings. In this setup, a smaller – but highly important – workload of 1TB was hosted on the same mega 1 PB deployment. Traditionally, such a workload can get starved, since it is 1000x smaller than the large workload. Moreover, the large workload was dominating the cluster with 7M TPS while the smaller one had “only” 280K TPS. Nevertheless, when assigned a priority, the smaller workload reduced its latency by half, to only 1-2 ms for its P99.
| Workload (in tps) | Application: 200k R/W | User: 5M 80/20 R/W | ||
| before: 1000 shares |
after: 1000 shares |
before: 1000 shares |
after: 500 shares |
|
| Write latency (in ms) | 0.682 P 50 2.454 P99 |
0.354 P50 1.184 P99 |
0.326 P50 1.252 P99 |
0.440 P50 3.244 P99 |
| Read latency (in ms) | 1.195 P50 4.555 P99 |
0.855 P50 3.731 P99 |
0.744 P50 3.709 P99 |
1.043 P50 6.455 P99 |
To summarize, ScyllaDB allows you to scale to any workload size, and to consolidate multiple workloads into a single operational cluster.
Dive into the Details…and Lessons Learned
But that’s just the tip of the iceberg. If you’re serious about petabyte-scale performance, details about how we got these results – and how you can conduct your own petabyte-scale benchmarks – are critical. That’s where the paper, What We Learned Benchmarking Petabyte-Scale Workloads with ScyllaDB, comes in. Get the PDF for:

- Details on how we configured the petabyte-scale benchmark
- A deeper look at workload prioritization and its impact
- Tips and tricks that might benefit others planning their own petabyte-scale benchmark






