
Somehow two months have passed since ScyllaDB Summit 24. Thinking back on the event, so much has changed since our inaugural ScyllaDB Summit, when ~100 people gathered in San Jose, CA in 2016. The ScyllaDB database, company, and community have all developed quite substantially. But one thing remains the same: hearing about what our users are achieving with ScyllaDB is still my favorite part of the conference.
I want to share some of the highlights from these great tech talks by our users and encourage you to watch the ones that are most relevant to your situation. As you read/watch, you will notice that some of the same themes appear across multiple talks:
- Moving to ScyllaDB to simplify the tech stack and operations
- Growing demand for a database that’s not tied to a specific cloud vendor
- Users unwilling to compromise between low latency, high throughput, and cost-effectiveness
ReversingLabs
The Strategy Behind ReversingLabs’ Massive Key-Value Migration
Martina Alilović Rojnić, Software Architect, ReversingLabs
About: ReversingLabs offers a complete software supply chain security and malware analysis platform. ReversingLabs data is used by more than 65 of the world’s most advanced security vendors and their tens of thousands of security professionals.
Takeaways: Martina is a fantastic storyteller, and she had a rather impressive story to tell.
ReversingLabs collects a massive amount of file samples daily and analyzes them both statically and dynamically. They currently have around 20B samples in their data set, mostly malware. These samples generate over 300TB of metadata, which is then exposed to around 400 services and various feeds.
Not surprisingly, the system architecture they designed when they were a scrappy startup well over a decade ago doesn’t suit their 2024 scale. They recognized that their initial Postgres-based architecture was not sustainable back in 2011, and they built their own simple key-value store that met their specific needs (being able to handle a ridiculous amount of data extremely efficiently). Ten years later, the company had grown significantly and they recognized they were reaching the limits of that custom key-value implementation.
They selected ScyllaDB, as you can guess. But what’s most interesting is how they pulled off this massive migration flawlessly, and with zero downtime. As I said at the start, Martina is a great storyteller – so I strongly encourage you to learn about their strategy directly from her.
Supercell
Real-Time Persisted Events at Supercell
Edvard Fagerholm, Senior Server Engineer, Supercell
About: Supercell is the brand behind the popular global games Hay Day, Clash of Clans, Boom Beach, Clash Royale, and Brawl Stars. Supercell offers free-to-play games that yield profits through in-game microtransactions.
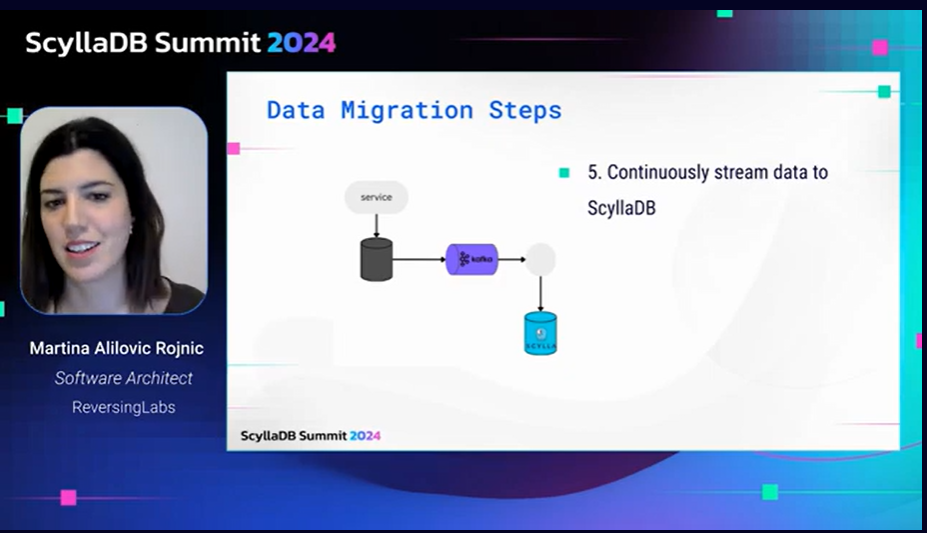
Takeaways: Supercell recently started on an application that goes along with wildly popular video games which each have generated over $1B in revenue. Basically, they transformed an existing Supercell ID implementation to support an in-game social network that lets players communicate with each other and see what their friends are currently doing within the games. Every player update generates an event, which is immediately sent to an API endpoint, broadcasted out to the appropriate parties, and saved to ScyllaDB.
In his tech talk, Edvard shared the story behind this social network’s implementation. I think we were all shocked to learn that the social network component of this system, used by over 200M players per month, is developed and run by a single backend engineer. That’s why the team wanted the implementation to be as efficient, flexible, and simple as possible, with a high level of abstraction. And to store the many events generated by all the players changing levels, updating avatars, etc., they needed a database that handled many small writes, easily supported a hierarchical data model, had low latency, and relieved that one backend engineer from having to deal with all the cluster management.
We’re honored that they selected ScyllaDB Cloud for this task. See the video for examples of how they modeled data for ScyllaDB as well as a detailed look at how they built the broader system architecture that ScyllaDB plugs into.
Tractian
MongoDB vs ScyllaDB: Tractian’s Experience with Real-Time ML
JP Voltani, Director of Engineering, Tractian
About: Tractian is an industrial asset monitoring company that uses AI to predict mechanical failures. They use sensors, edge computing hardware, and AI models to monitor industrial machines and identify potential failures based on vibrations and frequency patterns.
Takeaways: The team at Tractian does a first-class job across the board: database POCs, benchmarking, migrations, and even award-worthy video production. Kudos to them for amazing skill and initiative, all around!
With over 6 languages and 8 databases in the young and growing organization’s tech stack, they are clearly committed to adopting whatever technology is the best match for each of their use cases. And that’s also why they moved away from MongoDB when their AI model workloads increased over 2X in a single year and latencies also spiked beyond the point where scaling and tuning could help. They evaluated Postgres and ScyllaDB, with extensive benchmarking across all three options. Ultimately, they moved to ScyllaDB Cloud because it met their needs for latency at scale. Interestingly, they saw the data modeling rework required for moving from MongoDB to ScyllaDB as an opportunity, not a burden. They gained 10x better throughput with 10x better latency, together.
Watch the session to get all the details on their MongoDB to ScyllaDB migration blueprint
Discord
So You’ve Lost Quorum: Lessons From Accidental Downtime
Bo Ingram, Staff Software Engineer, Persistence Infrastructure, Discord
About: Discord is “a voice, video, and text app that helps friends and communities come together to hang out and explore their interests — from artists and activists, to study groups, sneakerheads, plant parents, and more. With 150 million monthly users across 19 million active communities, called servers, Discord has grown to become one of the most popular communications services in the world.”
Takeaways: Last year, Bo Ingram shared why and how Discord’s persistence team recently completed their most ambitious migration yet: moving their massive set of trillions of messages from Cassandra to ScyllaDB. This year, we were honored to have him back to share lessons from a very stressful Monday at Discord. Bo shared the inside perspective on an outage with one of their ScyllaDB clusters, showing how a stressed ScyllaDB cluster looks and behaves during an incident. If you watch this session, you will learn about how to diagnose issues in your clusters, see how external failure modes manifest in ScyllaDB, and how you can avoid making a fault too big to tolerate.
Bonus: Bo just wrote a great book on using ScyllaDB! If you plan to run ScyllaDB at scale, make sure you read this book before going to production. Bo captured years of high scalability practices, wrapped in friendly and fun packaging. You can get early access to a preview (free) at https://lp.scylladb.com/scylladb-in-action-book-offer. That includes a 45% discount on the complete book, which is being released quite soon.
Zee
CTO Insights: Steering a High-Stakes Database Migration
Kishore Krishnamurthy, CTO, ZEE5
Tracking Millions of Heartbeats on Zee’s OTT Platform
Srinivas Shanmugam, Principal Architect, ZEE5
Jivesh Threja, Senior Software Engineer, ZEE5
About: Zee is a 30-year-old publicly-listed Indian media and entertainment company. ZEE5 is their premier “over the top” (OTT) streaming service, available in over 190 countries with 150M monthly active users.
Takeaways: It’s honestly hard to believe that we just started working with Zee last year. They fast became power users, especially after navigating two major migrations – from DynamoDB, RDS (PostgreSQL), Redis, and Solr to ScyllaDB as well as a parallel migration to Google Cloud. The fact that these migrations went so smoothly is a great testament to the leadership of CTO Kishore Krishnamurthy. His keynote provides rapid-fire insight into what was going on through his head before, during, and after those migration processes.
Zee engineers also provided an insightful tech talk on Zee’s heartbeat API, which was the primary use case driving their consideration of ScyllaDB. Heartbeat lies at the core of Zee’s playback experience, security, and recommendation systems. They currently process a whopping 100B+ heartbeats per day!
Scaling up their previous heartbeats architecture to suit their rapid growth was cost-prohibitive with their previous databases. Jivesh and Srinivas outlined the technical requirements for the replacement (cloud-neutrality, multi-tenant readiness, simplicity of onboarding new use cases, and high throughput and low latency at optimal costs) and how that led to ScyllaDB. Then, they explained how they achieved their goals through a new stream processing pipeline, new API layer, and data (re)modeling that ultimately added up to 5X cost savings (from 744K to 144K annually) and single-digit millisecond P99 read latency. It all wraps up with an important set of lessons learned that anyone using or considering ScyllaDB should take a look at.

Digital Turbine (with SADA)
Radically Outperforming DynamoDB @ Digital Turbine with SADA and Google Cloud
Joseph Shorter, VP of Platform Architecture, Digital Turbine
Miles Ward, CTO, SADA
About: Digital Turbine is a mobile advertising, app delivery, and monetization ecosystem adopted by mobile carriers and OEMs. Their technology is deployed on ~100M mobile phones and drives 5B app installs.
Takeaways: First off, I think Miles and Joe deserve their own talk show. These are two great technologists and really cool people; it’s fun to watch them having so much fun talking about serious business-critical technology challenges.
After some fun intros, Miles and Joe walked through why DynamoDB was no longer meeting their needs. Basically, Digital Turbine’s write performance wasn’t where they hoped it would be and getting the performance they really wanted would have required even higher costs. On top of that, Digital Turbine had already decided to move to GCP. They approached SADA, looking for a way to get better performance and migrate without radically refactoring their platform. Joe and team were sold on the fact that ScyllaDB offered Alternator, a DynamoDB-compatible API that let them move with minimal code changes (less than one sprint).
They were pleasantly surprised to find that it not only improved their performance, but also came at a much lower cost due to ScyllaDB’s inherent efficiency. While DynamoDB was throttling them at 1,400 OPS, ScyllaDB wasn’t even breaking a sweat. That’s great to hear!

Watch Digital Turbine and SADA
JioCinema
Discover the Unseen: Tailored Recommendation of Unwatched Content
Charan Kamal, Back End Developer, JioCinema
Harshit Jain, Software Engineer, JioCinema
About: JioCinema is an Indian over-the-top media streaming service owned by Viacom18, a joint venture of Reliance Industries and Paramount Global. They feature top Indian and international entertainment, including live sports (including IPL cricket and NBA basketball), new movies, live sports, HBO originals, and more.
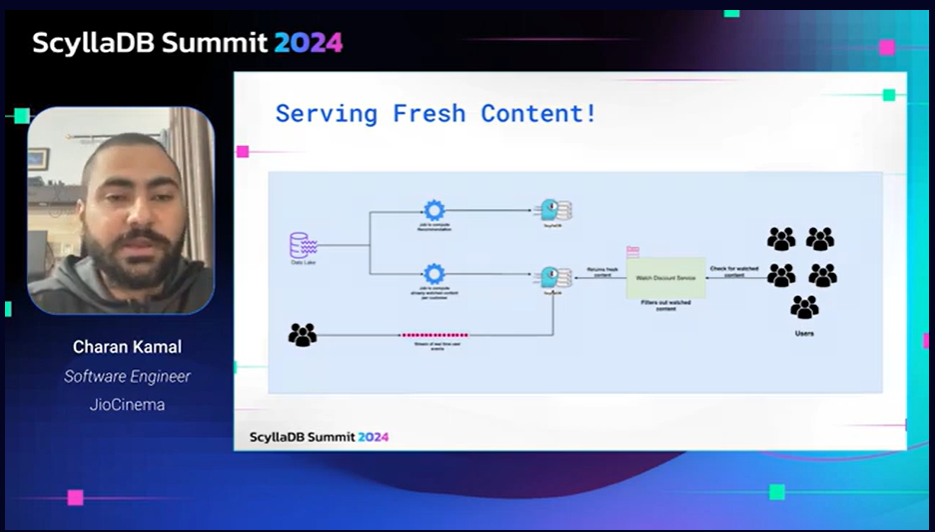
Takeaways: It was interesting to see how JioCinema tackled the challenge of ensuring that the “prime real estate” of recommended content lists don’t include content that the viewer has already watched. This is a common concern across media streamers – or at least should be – and I’m impressed by the innovative way that this team approached it.
Specifically, they used Bloom filters. They explored different options, but discovered that the most common ones required significant tradeoffs. Building their own in-memory Bloom filters offered low latency, but implementing it at the scale required was going to require too much work given their core focus. Redis was ruled out due to the deployment complexity required to maintain high availability and because Redis’ cost structure (pay for every operation) was going to be prohibitive given their 10M daily users and big events with 20M concurrent users. ScyllaDB also worked well, and with a cost structure that worked better for this rapidly growing service. In the video, Charan shares some good technical nuggets about how they implemented the Bloom filter solution with ScyllaDB. He also covers other features they liked in ScyllaDB, such as multi-region, local quorum, TTL for auto expiration, and high cardinality of key partitions.
Expedia
Inside Expedia’s Migration to ScyllaDB for Change Data Capture
Jean Carlo Rivera Ura, NoSQL Database Engineer III, Expedia
Mani Rangu, Database Administrator III, Expedia
About: Expedia is one of the world’s leading full-service online travel brands helping travelers easily plan and book their whole trip with a wide selection of vacation packages, flights, hotels, vacation rentals, rental cars, cruises, activities, attractions, and services.
Takeaways: Expedia shared their first ScyllaDB use case back in 2021. That was for an application that aggregates data from multiple systems, like hotel location info, third-party data, etc. with the goal of single-digit millisecond P99 read response time.
The new use case presented at this year’s ScyllaDB Summit was related to their identity cluster, which numerous Expedia applications rely on for user authentication. If it goes down, users can’t log in. They were previously running on Cassandra and using Cassandra’s CDC to capture changes and stream them to a Kafka cluster using Debezium Connector. They grew frustrated by the fact that writes to the CDC-enabled tables were rejected whenever the Debezium Connector stopped consuming events (which happened all too often for their liking).
Upon learning that ScyllaDB offered a straightforward and uncomplicated CDC implementation, they planned their move. Watch their talk to hear their breakdown of the two migration options they considered (SSTableLoader and the Spark-based ScyllaDB Migrator), get a step-by-step look at how they migrated, and learn what they’ll do differently when they migrate additional use cases over from Cassandra to ScyllaDB.

ShareChat
Getting the Most Out of ScyllaDB Monitoring: ShareChat’s Tips
Andrei Manakov, Staff Software Engineer, ShareChat
About: ShareChat is the leading social media platform in India. Between the ShareChat app and Moj (short-form video), they serve a user base of 400M users – and rapidly growing!
Takeaways: ShareChat is now starting their second year as a ScyllaDB user, which is pretty amazing given that their best practices are among the most sophisticated of all of our users. ShareChat has been a generous contributor to our community across ScyllaDB Summit as well as P99 CONF; I personally appreciate that and I know our community is always eager to learn what they’re sharing next.
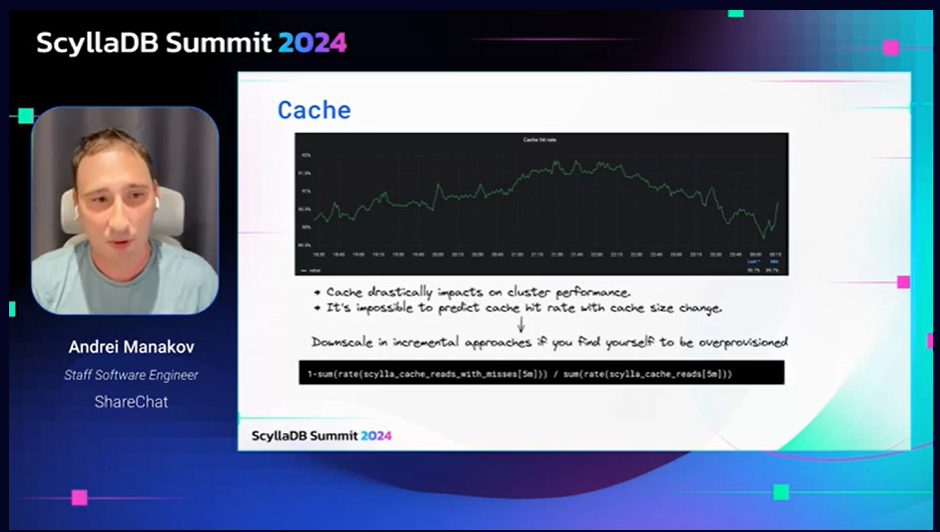
The latest addition to the ShareChat library of best practices is Andrei Manakov’s talk on how they’ve really customized monitoring to their specific needs and preferences for Moj, their TikTok-like short video app with 20M daily active users and 100M monthly active users. Here, ScyllaDB is used for the ML feature store that powers users’ feeds. Andrei walks us through how they’ve used the ScyllaDB Monitoring Stack to optimize driver usage, measure the impact of changing compaction strategies, monitor cluster capacity, and more.
Bonus: In case anyone wants background on why and how ShareChat moved to ScyllaDB, we’ve also added the great introductory talk by Geetish Nayak to the on-demand library. He covers the pressure driving their database migration, why and how they implemented ScyllaDB for a still-growing number of use cases, their migration strategy, and the best practices they developed for working with ScyllaDB.
Bonus Session for Live Attendees Only
Speaking of bonuses – live attendees were also treated to an additional user tech talk by a major media streaming provider. We don’t have permission to share it following that live broadcast, but here are some high-level takeaways:
- The team previously used Cassandra for their “Continue Watching” use case, but went looking for alternatives due to GC spikes, complex CDC, and its inability to take advantage of the modern hardware they had invested in
- They considered DynamoDB because of its similar data structure, but based on their data size (>10TB) and throughput (170k+ WPS and 78k+ RPS), they felt DynamoDB was “like just burning money”
- They conducted a POC of ScyllaDB, led by the ScyllaDB team using 6x i4i.4xlarge nodes with RF 3, 3B records preloaded
- They were able to hit combined load with no errors, P99 read latency of 9ms, and P99 write latency < 1ms




