
3 perspectives on what shard-per-core involves and why it matters for teams who care about database performance. Also … puppies!
ScyllaDB is best known for 3 things: 1) Predictable database performance at scale 2) A shard-per-core architecture 3) Cute sea monsters
The monster’s cuteness speaks for itself – especially if you’ve seen the plushie version. But a little more explanation is often required to communicate what’s so special about the shard-per-core architecture, and how it contributes to ScyllaDB’s predictable performance at scale. That’s what we’ll cover in this article.
Below are three different perspectives on what shard-per-core involves and why it matters for teams who care about database performance:
- How Dor Laor (ScyllaDB Co-founder and CEO) first introduced the concept back when ScyllaDB launched in 2015
- The ScyllaDB power user perspective by Bo Ingram, author of ScyllaDB in Action and the monstrously popular ScyllaDB migration blog
- A more detailed look under the hood, explained by Tzach Livyatan (VP of Product) earlier this year at ScyllaDB Summit
Bonus: We’ll bring some puppies into the mix since (some) puppies are just as cute as the ScyllaDB monster.

The ScyllaDB Sea Monster with Baunilha
Dor Laor’s 2015 introduction: independent, lock-free processing across server cores
From a 2015 ScyllaDB feature on ZDNet
“Everybody does sharding in a cluster but usually the granularity is per server. We do it per core. The result is each of the shards within the server is fully independent, so there’s no need for locking. there are no regular threads that you need to protect your data structures.
The independence of the shard means there is no contention, with each one managing its own resources, whether that is a networking card, memory or the CPU itself.
Each shard has its own CPU, its own memory – it’s local to that node so it’s multi-socket friendly – that’s NUMA-friendly [non-uniform memory access]. It’s expensive to access memory between one core and one socket with memory that belongs to another socket.
Within a server, we have lots of such shards – exactly the amount of the x86 cores that exist in that server. The bigger the server grows with the newer CPUs that Intel produces, the better for us because we scale up linearly. In the relations between the cores, everything is independent.”
Bo Ingram’s power user’s perspective: predictable low latencies
From Bo’s new book, “ScyllaDB in Action”
“ScyllaDB’s biggest architectural difference is its shard-per-core architecture. Both Cassandra and ScyllaDB shard a data set across its various nodes via placement in a hash ring. ScyllaDB takes this further by leveraging the Seastar framework (https://seastar.io/) to shard data within a node, splitting it up per CPU-core and giving each shard its own CPU, memory, and network bandwidth allocation.
Cassandra does not follow this paradigm, however, and limits the sharding to only per node. If a data partition gets a large amount of requests, it can overwhelm the node, leading to cluster-wide struggles.

Performance justifies the rewrite. Both in benchmarks (https://thenewstack.io/benchmarking-apache-cassandra-40-nodes-vs-scylladb-4-nodes/) and in the wild (https://discord.com/blog/how-discord-stores-trillions-of-messages), ScyllaDB is faster, more consistent, and requires fewer servers to operate than Cassandra.”
Read more from ScyllaDB In Action – Free
Tzach Livyatan: Unraveling the threads towards linear scalability
From Tzach Livyatan’s keynote, “A Deep Dive into ScyllaDB’s Architecture”
“ScyllaDB was designed with performance in mind – in particular, high throughput and low latency. The shard-per-core design is fundamental for that.
Systems that aren’t as obsessed with performance tend to use a thread pool, with many threads competing for the same resources. At any given second, threads might be trying to get to memory, trying to get to disk, or trying to do something that requires synchronization – and they get blocked. The CPU will then context switch. When we profiled other databases, we found that this synchronization between the threads is often responsible for consuming the majority of the resources.
ScyllaDB takes a different approach, with a shard per core architecture. Each thread is pinned to a specific core. And each thread is assigned its own designated chunk of memory, its own designated chunk of network, and its own designated chunk of storage. As a result, there’s minimal interaction between the cores, and each can run independently in a very efficient way: it never context switches, it never waits.
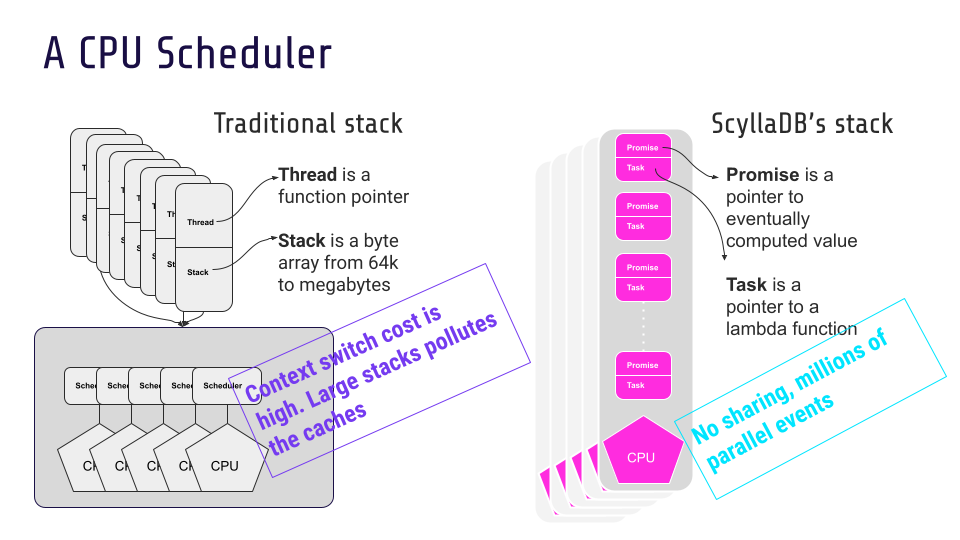
I think this is probably the most important design decision behind the high performance that users get from ScyllaDB. It also allows ScyllaDB to scale linearly with the number of cores.
If you deploy ScyllaDB on 16 cores, and then on 32 cores, you get exactly twice the performance. And if you double the cores again, you again get double the performance. Since each core is an independent shard, there is virtually no interaction between the cores and you can scale with the number of cores in a very efficient way.”
See Tzach’s complete ScyllaDB architecture deep dive here:
And now… puppies
If you’ve ever fed a group of puppies, you’ll recognize the top image here. There are 6 bowls of dog food and 6 puppies. But multiple puppies are fighting over a couple bowls of food, and a few bowls of food are totally empty. Food is spilled all over the ground as a result of the fights.

That’s like the shared thread architecture used by other systems, like Cassandra. When a job needs to be done, it’s basically thrown down to a thread pool, and a thread takes the job. However, the threads bump into each other – like our puppies. In the systems case, that could cause problems such as latency spikes.
In the lower image, you can see each puppy is happily eating from its own bowl of food. There’s no fighting and no waste. Similarly, ScyllaDB’s shard-per core architecture eliminates all that contention for resources. We take all of the system resources and all of the data and split it up evenly, based on the number of cores. Just like each puppy has its own portion of food, each shard has its own dedicated RAM, its own network, its own I/O, and its own piece of the data.
Coming soon…quantifying the impact of a shard-per-core architecture
Almost a year ago to the day, Dor Laor kicked off P99 CONF 23 with a shard-per-core deep dive that people are still talking about. His teaser:
Most software isn’t architected to take advantage of modern hardware. How does a shard-per-code and shared-nothing architecture help – and exactly what impact can it make? I will examine technical opportunities and tradeoffs, as well as share the results of a new benchmark study.
To give that talk the depth it deserves, we’ll write it up in a dedicated article. So stay tuned if you prefer to read. If you can’t wait, we invite you to watch it now.
See Dor’s Shard-Per-Core Keynote




