See the engineering behind real-time personalization at Tripadvisor’s massive (and rapidly growing) scale
What kind of traveler are you? Tripadvisor tries to assess this as soon as you engage with the site, then offer you increasingly relevant information on every click—within a matter of milliseconds. This personalization is powered by advanced ML models acting on data that’s stored on ScyllaDB running on AWS.
In this article, Dean Poulin (Tripadvisor Data Engineering Lead on the AI Service and Products team) provides a look at how they power this personalization. Dean shares a taste of the technical challenges involved in delivering real-time personalization at Tripadvisor’s massive (and rapidly growing) scale.
It’s based on the following AWS re:Invent talk:
Pre-Trip Orientation
In Dean’s words …
Let’s start with a quick snapshot of who Tripadvisor is, and the scale at which we operate. Founded in 2000, Tripadvisor has become a global leader in travel and hospitality, helping hundreds of millions of travelers plan their perfect trips. Tripadvisor generates over $1.8 billion in revenue and is a publicly traded company on the NASDAQ stock exchange. Today, we have a talented team of over 2,800 employees driving innovation, and our platform serves a staggering 400 million unique visitors per month – a number that’s continuously growing.
On any given day, our system handles more than 2 billion requests from 25 to 50 million users. Every click you make on Tripadvisor is processed in real time. Behind that, we’re leveraging machine learning models to deliver personalized recommendations – getting you closer to that perfect trip. At the heart of this personalization engine is ScyllaDB running on AWS. This allows us to deliver millisecond-latency at a scale that few organizations reach. At peak traffic, we hit around 425K operations per second on ScyllaDB with P99 latencies for reads and writes around 1-3 milliseconds.
I’ll be sharing how Tripadvisor is harnessing the power of ScyllaDB, AWS, and real-time machine learning to deliver personalized recommendations for every user. We’ll explore how we help travelers discover everything they need to plan their perfect trip: whether it’s uncovering hidden gems, must-see attractions, unforgettable experiences, or the best places to stay and dine. This [article] is about the engineering behind that – how we deliver seamless, relevant content to users in real time, helping them find exactly what they’re looking for as quickly as possible.
Personalized Trip Planning
Imagine you’re planning a trip. As soon as you land on the Tripadvisor homepage, Tripadvisor already knows whether you’re a foodie, an adventurer, or a beach lover – and you’re seeing spot-on recommendations that seem personalized to your own interests. How does that happen within milliseconds?

As you browse around Tripadvisor, we start to personalize what you see using Machine Learning models which calculate scores based on your current and prior browsing activity. We recommend hotels and experiences that we think you would be interested in. We sort hotels based on your personal preferences. We recommend popular points of interest near the hotel you’re viewing. These are all tuned based on your own personal preferences and prior browsing activity.
Tripadvisor’s Model Serving Architecture
Tripadvisor runs on hundreds of independently scalable microservices in Kubernetes on-prem and in Amazon EKS. Our ML Model Serving Platform is exposed through one of these microservices.
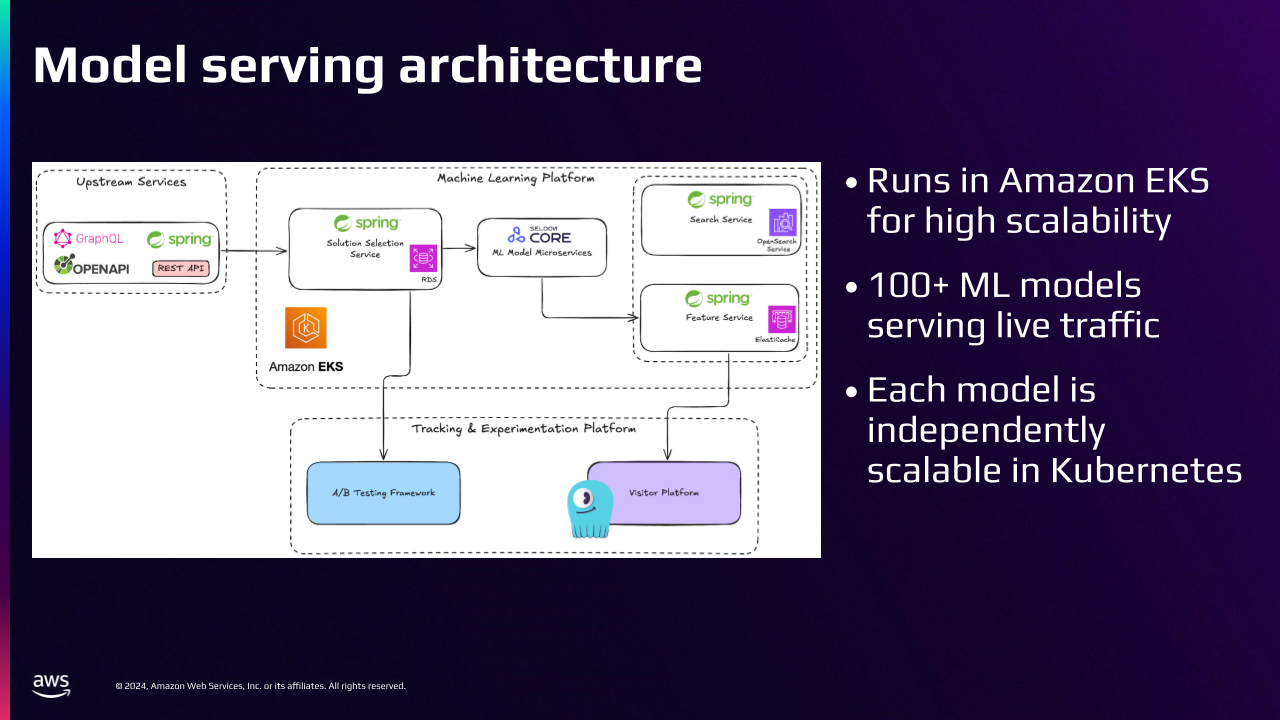
This gateway service abstracts over 100 ML Models from the Client Services – which lets us run A/B tests to find the best models using our experimentation platform. The ML Models are primarily developed by our Data Scientists and Machine Learning Engineers using Jupyter Notebooks on Kubeflow. They’re managed and trained using ML Flow, and we deploy them on Seldon Core in Kubernetes. Our Custom Feature Store provides features to our ML Models, enabling them to make accurate predictions
The Custom Feature Store
The Feature Store primarily serves User Features and Static Features. Static Features are stored in Redis because they don’t change very often. We run data pipelines daily to load data from our offline data warehouse into our Feature Store as Static Features.
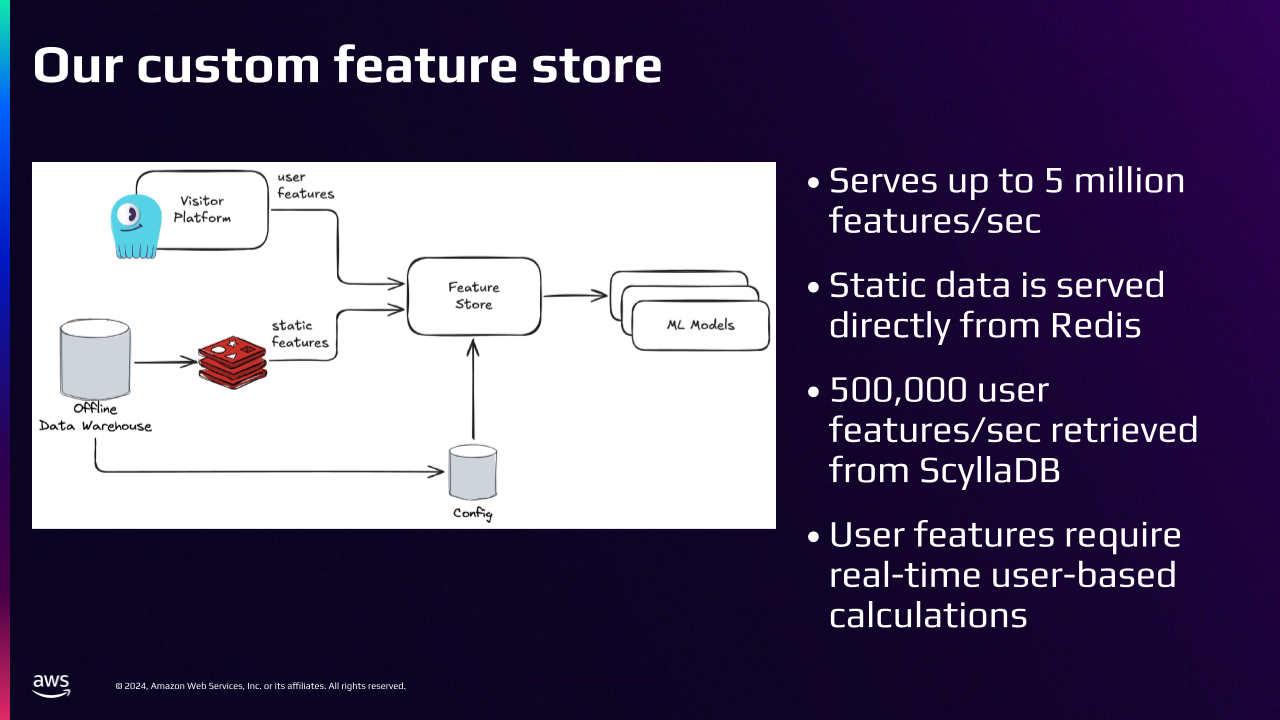
User Features are served in real time through a platform called Visitor Platform. We execute dynamic CQL queries against ScyllaDB, and we do not need a caching layer because ScyllaDB is so fast.
Our Feature Store serves up to 5 million Static Features per second and half a million User Features per second.
What’s an ML Feature?
Features are input variables to the ML Models that are used to make a prediction. There are Static Features and User Features.
Some examples of Static Features are awards that a restaurant has won or amenities offered by a hotel (like free Wi-Fi, pet friendly or fitness center).
User Features are collected in real time as users browse around the site. We store them in ScyllaDB so we can get lightning fast queries. Some examples of user features are the hotels viewed over the last 30 minutes, restaurants viewed over the last 24 hours, or reviews submitted over the last 30 days.
The Technologies Powering Visitor Platform
ScyllaDB is at the core of Visitor Platform. We use Java-based Spring Boot microservices to expose the platform to our clients. This is deployed on AWS ECS Fargate. We run Apache Spark on Kubernetes for our daily data retention jobs, our offline to online jobs. Then we use those jobs to load data from our offline data warehouse into ScyllaDB so that they’re available on the live site. We also use Amazon Kinesis for processing streaming user tracking events.
The Visitor Platform Data Flow
The following graphic shows how data flows through our platform in four stages: produce, ingest, organize, and activate.
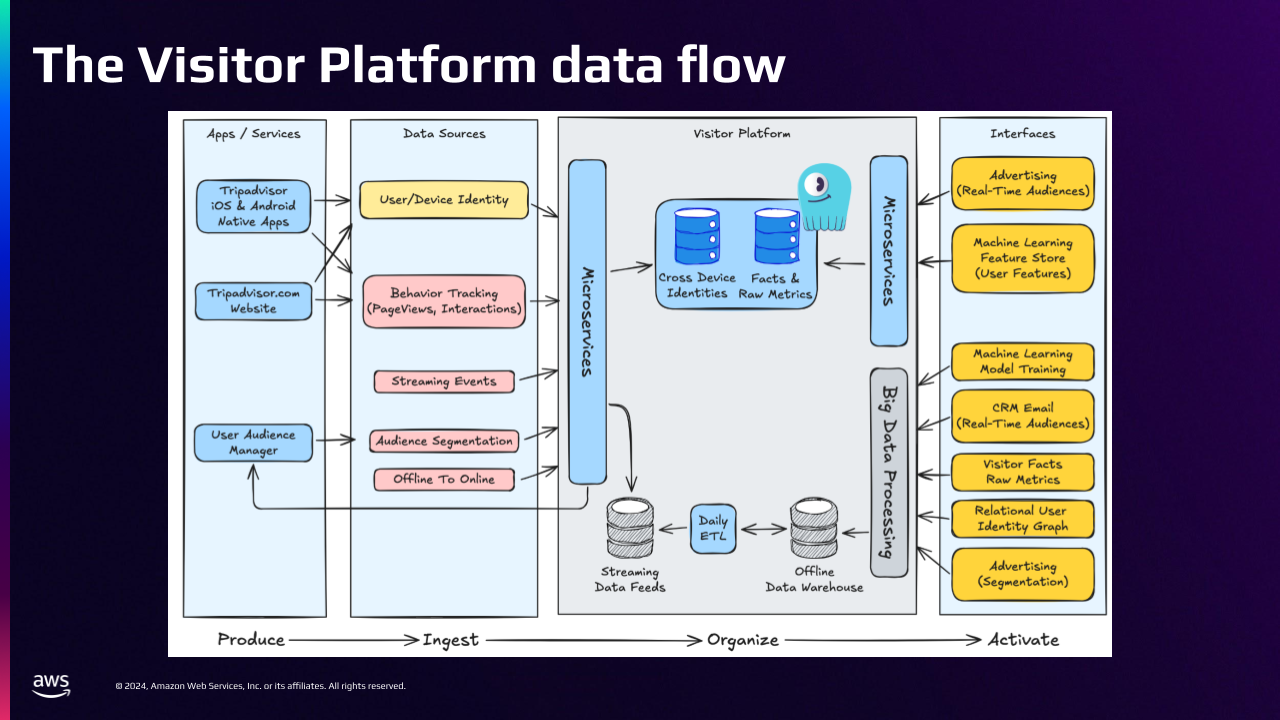
Data is produced by our website and our mobile apps. Some of that data includes our Cross-Device User Identity Graph, Behavior Tracking events (like page views and clicks) and streaming events that go through Kinesis. Also, audience segmentation gets loaded into our platform.
Visitor Platform’s microservices are used to ingest and organize this data. The data in ScyllaDB is stored in two keyspaces:
- The Visitor Core keyspace, which contains the Visitor Identity Graph
- The Visitor Metric keyspace, which contains Facts and Metrics (the things that the people did as they browsed the site)
We use daily ETL processes to maintain and clean up the data in the platform. We produce Data Products, stamped daily, in our offline data warehouse – where they are available for other integrations and other data pipelines to use in their processing.
Here’s a look at Visitor Platform by the numbers:
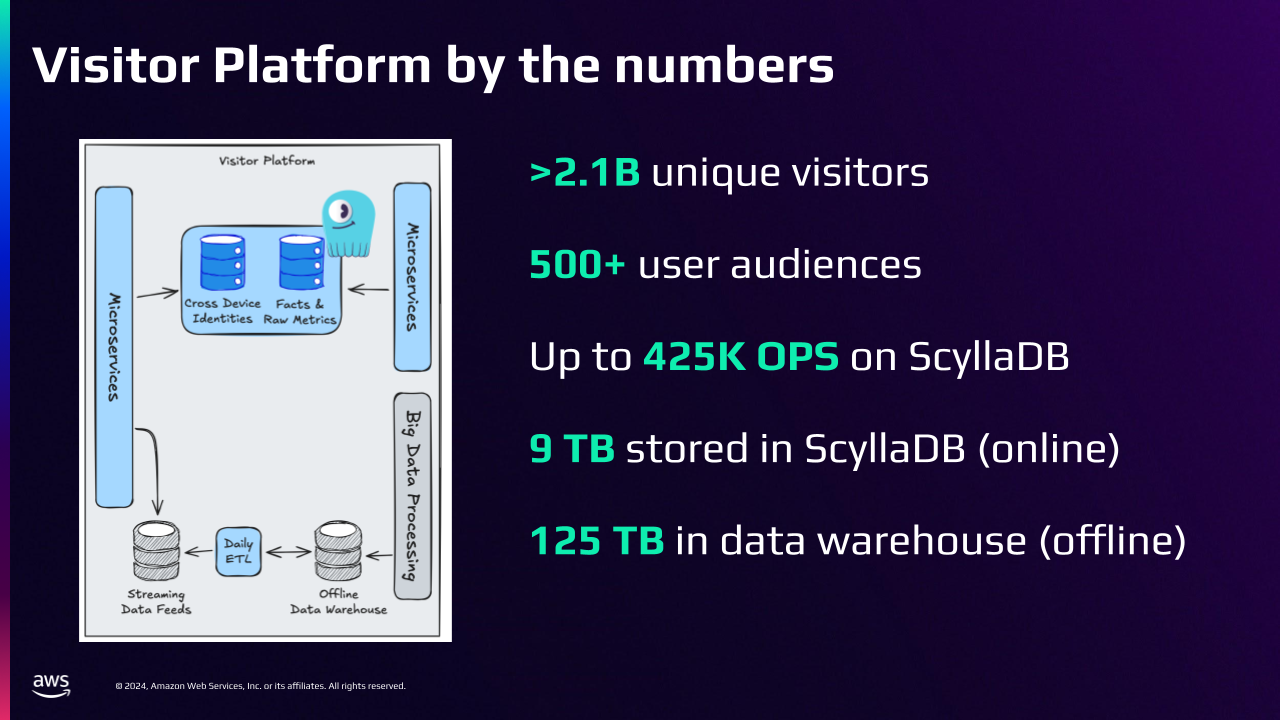
Why Two Databases?
Our online database is focused on the real-time, live website traffic. ScyllaDB fills this role by providing very low latencies and high throughput. We use short term TTLs to prevent the data in the online database from growing indefinitely, and our data retention jobs ensure that we only keep user activity data for real visitors. Tripadvisor.com gets a lot of bot traffic, and we don’t want to store their data and try to personalize bots – so we delete and clean up all that data.

Our offline data warehouse retains historical data used for reporting, creating other data products, and training our ML Models. We don’t want large-scale offline data processes impacting the performance of our live site, so we have two separate databases used for two different purposes.
Visitor Platform Microservices
We use 5 microservices for Visitor Platform:
- Visitor Core manages the cross-device user identity graph based on cookies and device IDs.
- Visitor Metric is our query engine, and that provides us with the ability for exposing facts and metrics for specific visitors. We use a domain specific language called visitor query language, or VQL. This example VQL lets you see the latest commerce click facts over the last three hours.
- Visitor Publisher and Visitor Saver handle the write path, writing data into the platform. Besides saving data in ScyllaDB, we also stream data to the offline data warehouse. That’s done with Amazon Kinesis.
- Visitor Composite simplifies publishing data in batch processing jobs. It abstracts Visitor Saver and Visitor Core to identify visitors and publish facts and metrics in a single API call.
Roundtrip Microservice Latency
This graph illustrates how our microservice latencies remain stable over time.
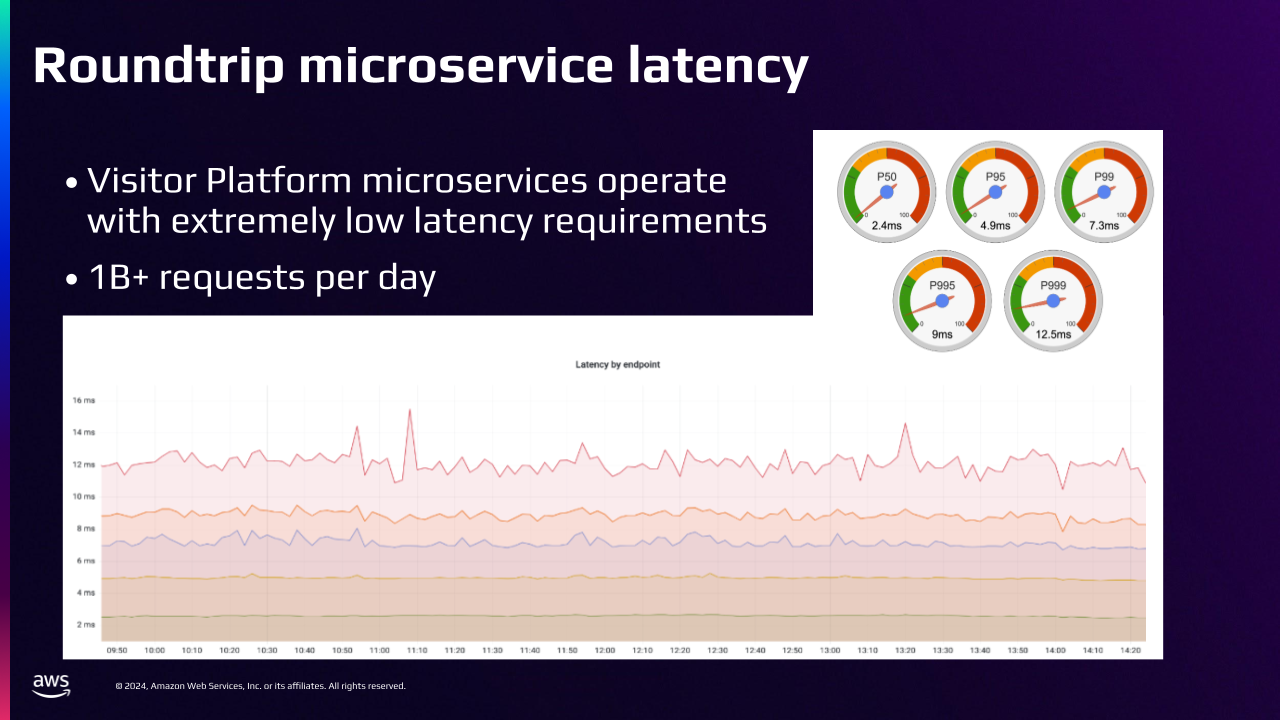
The average latency is only 2.5 milliseconds, and our P999 is under 12.5 milliseconds. This is impressive performance, especially given that we handle over 1 billion requests per day.
Our microservice clients have strict latency requirements. 95% of the calls must complete in 12 milliseconds or less. If they go over that, then we will get paged and have to find out what’s impacting the latencies.
ScyllaDB Latency
Here’s a snapshot of ScyllaDB’s performance over three days.
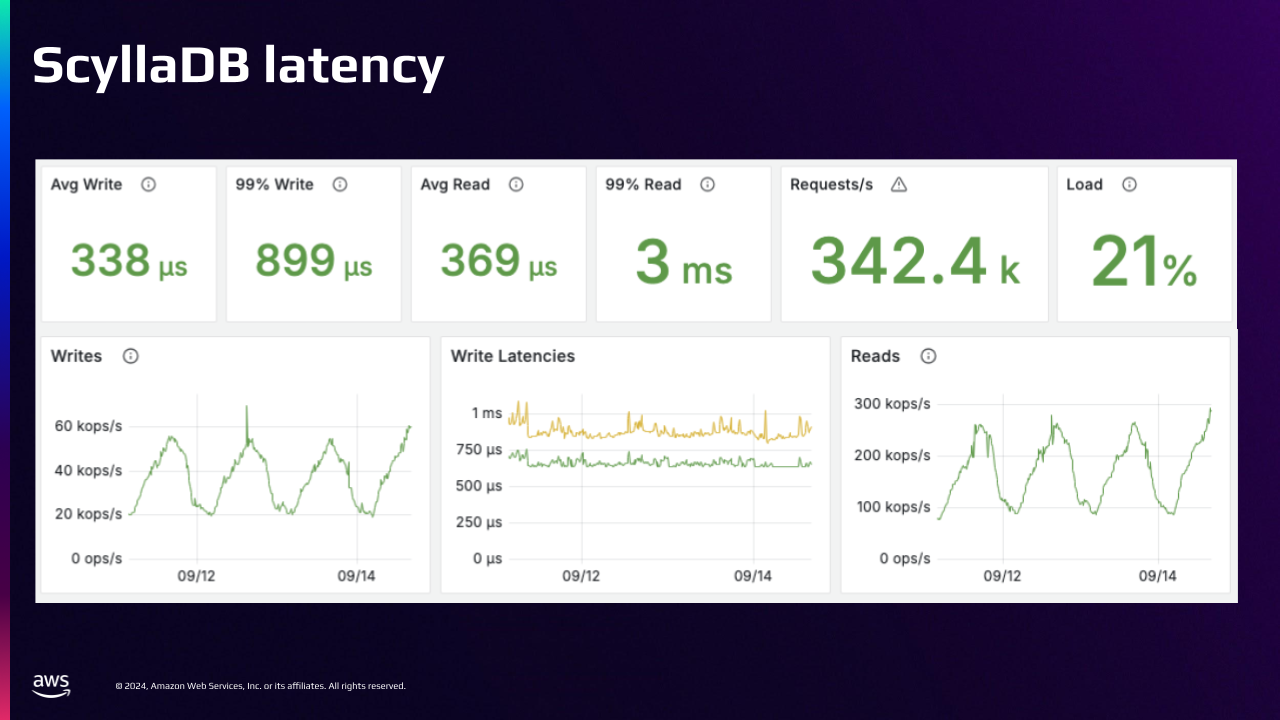
At peak, ScyllaDB is handling 340,000 operations per second (including writes and reads and deletes) and the CPU is hovering at just 21%. This is high scale in action!
ScyllaDB delivers microsecond writes and millisecond reads for us. This level of blazing fast performance is exactly why we chose ScyllaDB.
Partitioning Data into ScyllaDB
This image shows how we partition data into ScyllaDB.
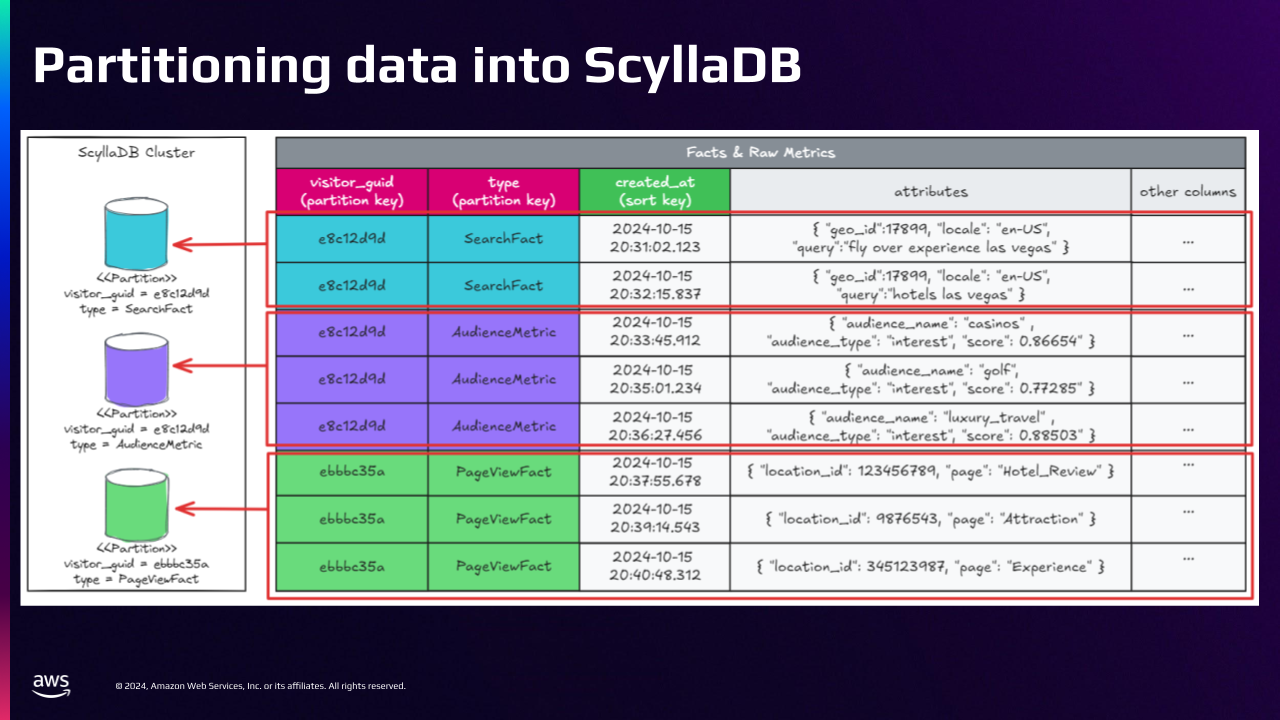
The Visitor Metric Keyspace has two tables: Fact and Raw Metrics. The primary key on the Fact table is Visitor GUID, Fact Type, and Created At Date. The composite partition key is the Visitor GUID and Fact Type. The clustering key is Created At Date, which allows us to sort data in partitions by date. The attributes column contains a JSON object representing the event that occurred there. Some example Facts are Search Terms, Page Views, and Bookings.
We use ScyllaDB’s Leveled Compaction Strategy because:
- It’s optimized for range queries
- It handles high cardinality very well
- It’s better for read-heavy workloads, and we have about 2-3X more reads than writes
Why ScyllaDB?
Our solution was originally built using Cassandra on-prem. But as the scale increased, so did the operational burden. It required dedicated operations support in order for us to manage the database upgrades, backups, etc. Also, our solution requires very low latencies for core components. Our User Identity Management system must identify the user within 30 milliseconds – and for the best personalization, we require our Event Tracking platform to respond in 40 milliseconds. It’s critical that our solution doesn’t block rendering the page so our SLAs are very low. With Cassandra, we had impacts to performance from garbage collection. That was primarily impacting the tail latencies, the P999 and P9999 latencies.

We ran a Proof of Concept with ScyllaDB and found the throughput to be much better than Cassandra and the operational burden was eliminated. ScyllaDB gave us a monstrously fast live serving database with the lowest possible latencies.
We wanted a fully-managed option, so we migrated from Cassandra to ScyllaDB Cloud, following a dual write strategy. That allowed us to migrate with zero downtime while handling 40,000 operations or requests per second. Later, we migrated from ScyllaDB Cloud to ScyllaDB’s “Bring your own account” model, where you can have the ScyllaDB team deploy the ScyllaDB database into your own AWS account. This gave us improved performance as well as better data privacy.
This diagram shows what ScyllaDB’s BYOA deployment looks like.
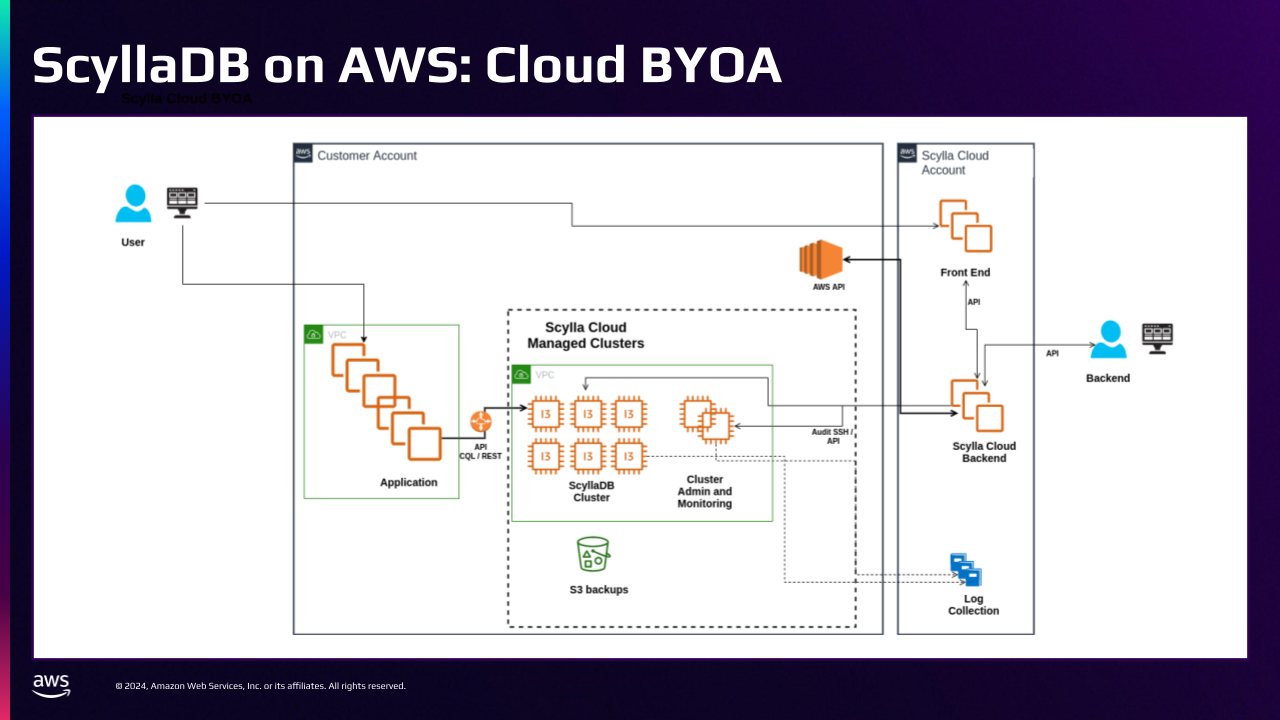
In the center of the diagram, you can see a 6-node ScyllaDB cluster that is running on EC2. And then there’s two additional EC2 instances.
- ScyllaDB Monitor gives us Grafana dashboards as well as Prometheus metrics.
- ScyllaDB Manager takes care of infrastructure automation like triggering backups and repairs.
With this deployment, ScyllaDB could be co-located very close to our microservices to give us even lower latencies as well as much higher throughput and performance.
Wrapping up, I hope you now have a better understanding of our architecture, the technologies that power the platform, and how ScyllaDB plays a critical role in allowing us to handle Tripadvisor’s extremely high scale.

