TRACTIAN’s ML model workloads increased over 2X in a year. Here’s why they changed databases and their lessons learned
What happens when you hit a database scaling wall? Since TRACTIAN, an AI-driven industrial monitoring company, is all about preventing problems, they didn’t want to wait and see. After the company’s ML workloads doubled in a year, their industrial IoT platform was experiencing unsolvable performance degradation. With more rapid growth on the horizon, their engineering leaders decided to rethink their distributed data system before they hit MongoDB’s breaking point.
JP Voltani, TRACTIAN’s Director of Engineering, recently shared the team’s experiences at ScyllaDB Summit. If we gave out Academy Awards for production, this one would have been the clear winner (all credit to the TRACTIAN team). So, be sure to watch this quick look at some impressive scaling work.
Enjoy engineering case studies like this? Choose your own adventure through 60+ tech talks at Monster Scale Summit (free + virtual). You can learn from experts like Martin Kleppmann, Kelsey Hightower and Gwen Shapira, plus engineers from Discord, Disney+, Slack, Atlassian, Uber, Canva, Medium, Cloudflare, and more.
Key Takeaways
A few key takeaways:
- TRACTIAN was reaching a critical inflection point when their sensor network grew more than 2x in a single year. MongoDB struggled, even after the team’s valiant optimization and scaling attempts. The constant stream of time-series sensor data (vibration, temperature, energy consumption) caused performance degradation that could compromise their latency targets.
- The team wanted a database architecture specifically designed for high-throughput, time-partitioned data workloads, which led them to ScyllaDB. They benchmarked ScyllaDB vs Cassandra, Postgres, and MongoDB. The results showed a 10x performance improvement with ScyllaDB, and they appreciated its operational simplicity compared to Cassandra.
- The TRACTIAN team moved their most performance-critical workloads to ScyllaDB while maintaining MongoDB for other use cases, exemplifying their “right tool for the job” philosophy. They experienced a 10x improvement in throughput and latency with ScyllaDB.
- TRACTIAN applied a four-phase migration process (dual writes → historical backfill → read switching → final validation). This phased approach maintained 99.95% availability while transitioning critical industrial IoT data pipelines.
- The team mapped their IoT workload to ScyllaDB by partitioning data by sensor ID and clustering by timestamp. This data modeling change improved query performance for time-window searches and eliminated the hotspot issues that had plagued their MongoDB implementation.
Here’s a lightly edited transcript…
Intro
Hello, everyone. My name is JP, and I’m the Director of Engineering at TRACTIAN. Today, I’m going to talk about our experience with real time machine learning using ScyllaDB. I will start talking about what TRACTIAN is and what we do, what our infrastructure looks like, why we migrated away from MongoDB for some workloads, our ScyllaDB migration process, and what is next for us.
At TRACTIAN, we build solutions for industrial maintenance. We want to empower the maintenance teams around the globe with the best in class hybrid and AI assisted software.
We have three products:
- The Smart Trac is a vibration and temperature sensor that is able to detect more than 70 types of failures in rotating machines.
- The TracOS is a system with everything needed to manage the operations of maintenance teams on the plant floor, enabling mobile and offline operations.
- The Energy Trac is a sensor that is able to monitor energy consumption, efficiency and electrical quality.
Together, these products form a very concise solution that works seamlessly with one another – bringing a very Apple-like experience to industrial maintenance. We have already raised over $100M through VC funding, establishing a global footprint with customers across the Americas. We have three different headquarters: one in Brazil, one in Mexico, one in the USA. We have employees worldwide.
The TRACTIAN Tech Stack
Let’s talk about our tech stack. We have a very straightforward approach to adopting new technologies: If it helps solve a real problem, we embrace it. For this reason, our tech stack is very modern and extensive. We use more than 80 databases and 6 different languages for our services. That allows us to leverage the strengths of each technology.
We have a microservices architecture with more than 30 services, ranging from APIs, consumers, producers and batch processes. They all handle more than 1500 events per second from different sources. And they do so with an average latency lower than 200 milliseconds and with 99.95% availability.
Here’s what our infrastructure looked like before ScyllaDB.
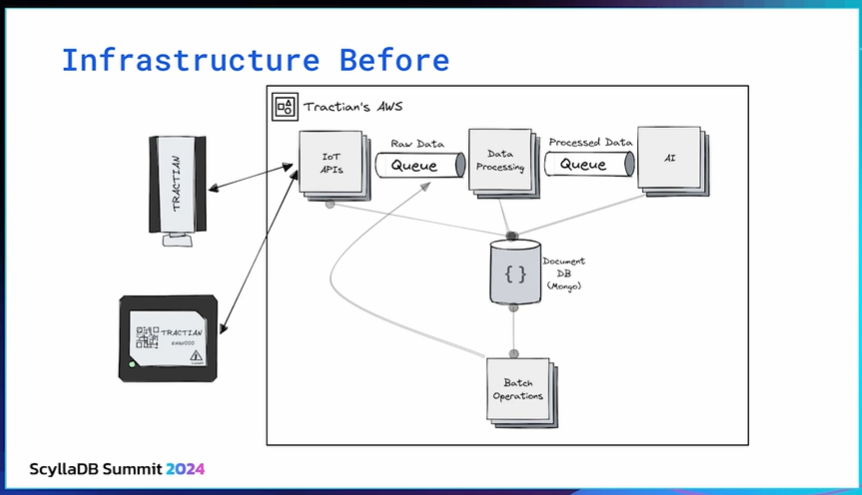
The sensor sent data to our APIs, and the APIs put the sensor data into Kafka topics. We had different services that would consume these topics to process the data– saving into MongoDB, into different collections. After that, we sent triggers to the AI pipeline to process the data.
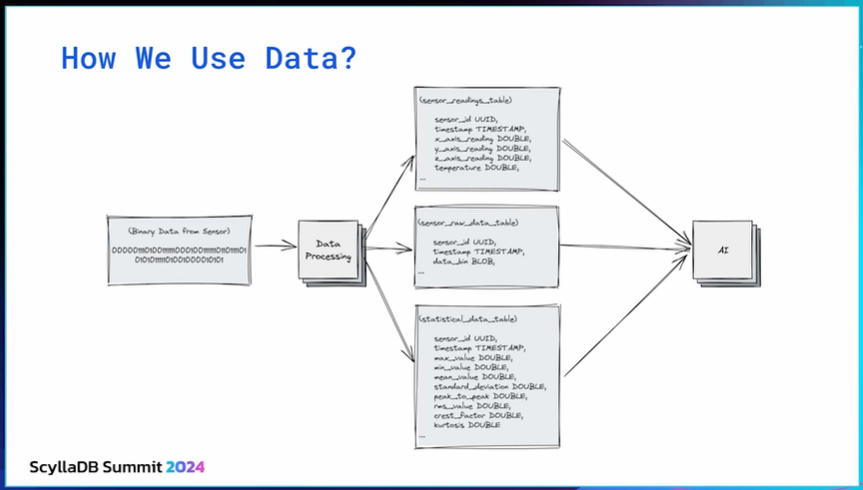
We start with a binary blob from the sensor and the processing services expand the data to different tables. Some use it for client visualizations, others as vectors for AI (training and inference).
Why They Evolved
As the company grew, the number of samples arriving to the system also grew. We saw the workloads increase over 2x in a single year, and the database needed to deal with that increase.
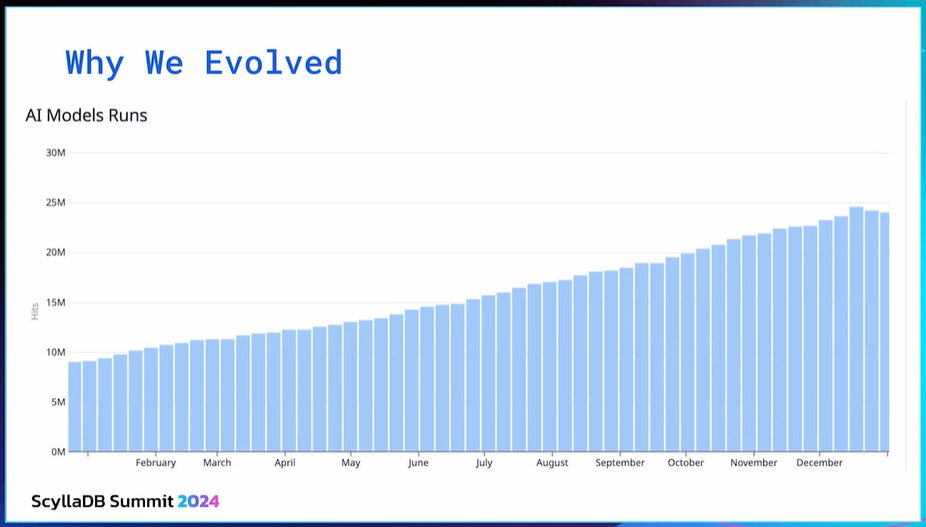
Unfortunately, even after upscale operations and optimizations, that was not the case with MongoDB. Performance degradation made us look for alternative solutions for our warehouse and AI workloads.
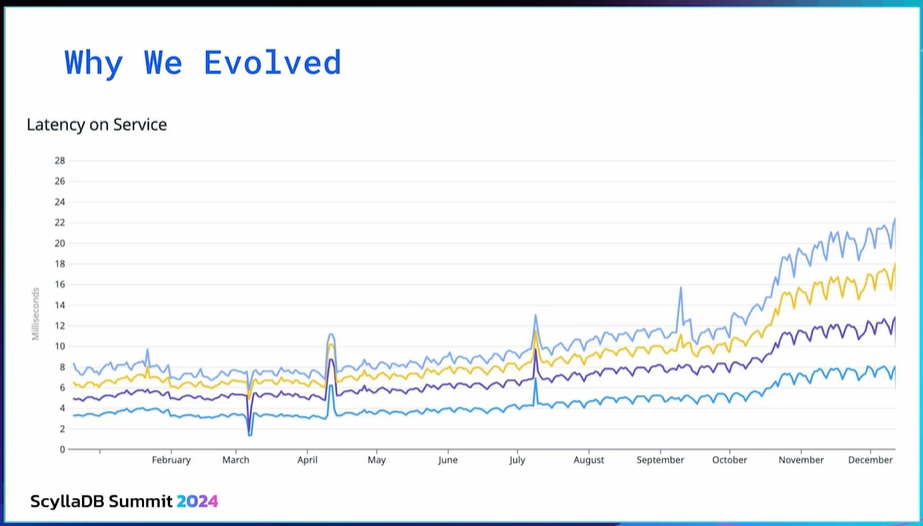
Why ScyllaDB
Why ScyllaDB? At the time, we already tested Cassandra. The results were promising, but some database operations, like upscaling, had some aspects that were not attractive to us. MongoDB was not handling the IoT workload very well, and we wanted something that was easier to scale. ScyllaDB showed itself to be a light at the end of the tunnel. We were searching for something really specific, and luckily ScyllaDB had a data model that fit our problem very well. Also, ScyllaDB’s database operations were way better than Cassandra’s.
This is just one example of how ScyllaDB’s data model works in favor of our workloads.

In this case, we have some binary data that we want to start partitioning by sensor ID and ordering by the timestamp. ScyllaDB will make this query for a specific ID in a time window very fast.
We had a plan on our hands. First, we created a new DSL. What would the tables on ScyllaDB look like? How would MongoDB data map to the new tables? After that, we did a bunch of theoretical benchmarks, which is basically testing with synthetic data. This is an easy and fast way to validate an idea. Then we did it all over again, but with real data. Sometimes synthetic tests fail to map some nuances of real data and miss things like partitions and hot spots. Other times, they fail to create a good mapping, and this only becomes visible when you test with real data. So, it’s important to not skip this step.
Next, we went into the weeds and refactored all the existing application code to use the new database. It’s important to have very, very clear success criteria. What are you trying to achieve with this migration? We had a very clear number of devices in mind that the new infrastructure should be able to handle.
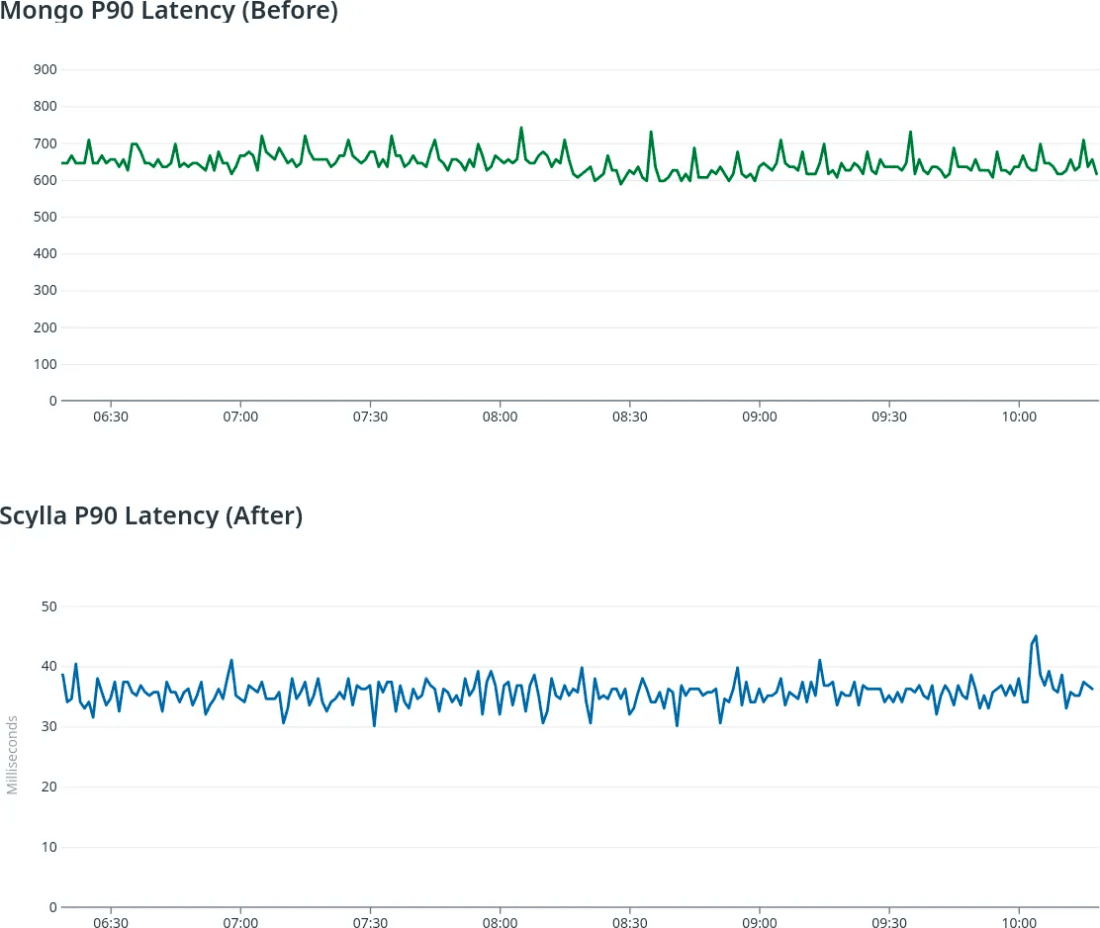
The test results came in favor of ScyllaDB. In some workloads, we saw an increase of 10x in throughput and latency.

Migration Strategy
Next, let’s talk about the migration game plan. We did everything live and without downtime. Initially, all the data was being written to MongoDB. After that, we started to write to both databases.
This was the first checkpoint of the migration.
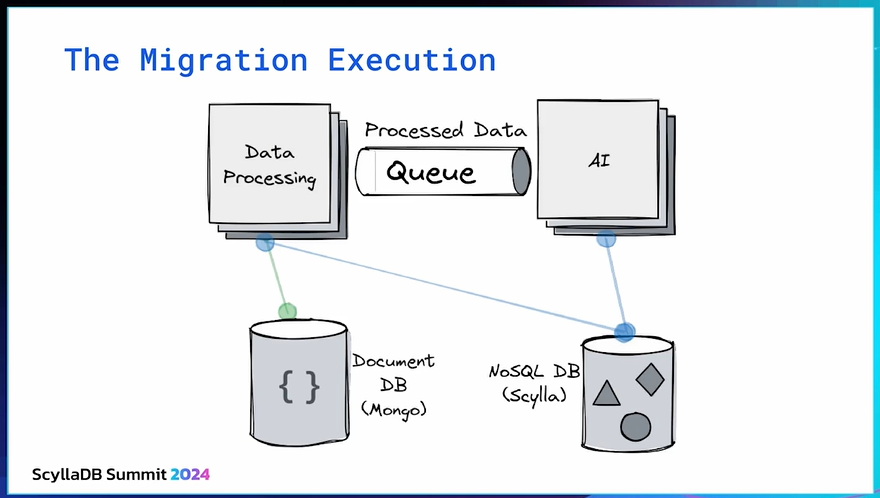
At this step, we checked to see if both databases agreed if the data was correct and if the initial performance test agreed with the benchmark ones. After that, we started our migration script that would backfill ScyllaDB with the historical data from MongoDB and check that no data was missing. Then, we switched the reads to occur on ScyllaDB, while continuing to write on MongoDB as a backup if any problems occurred.
This is how we did our online no downtime migration. The results speak for themselves.

Results
We have a great write read latency after migration and ScyllaDB has scaled very well with our increasing workload. Our infrastructure now has ScyllaDB as one of its backbones, and we still use MongoDB for other types of workloads – and also a bunch of other databases for other challenges.
Read more about TRACTIAN’s comparison of ScyllaDB vs MongoDB and PostgreSQL in ScyllaDB vs MongoDB vs PostgreSQL