Apache Cassandra Architecture FAQs
What is Apache Cassandra Architecture?
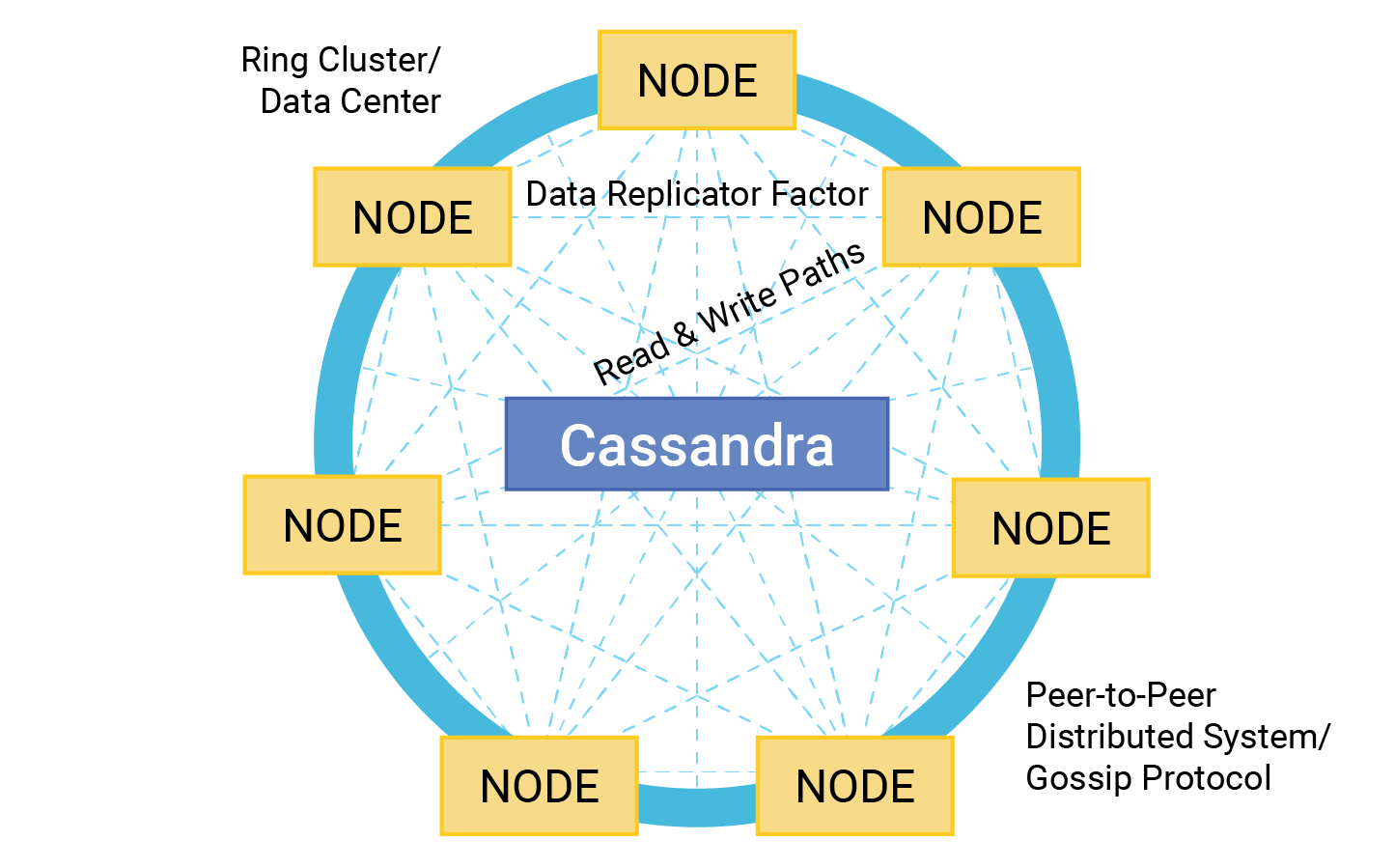
The architecture of Apache Cassandra generally looks like this:
- Peer-to-peer distributed system. All Cassandra nodes in the cluster are equal and communicate with each other without the need for a centralized coordinator, avoiding a single point of failure.
- Ring clusters. Apache Cassandra design architectures distribute data across the cluster in a ring, with each of the nodes in a cluster responsible for a range of data determined by a hashing algorithm.
- Data replication factor. Cassandra replicates data files across a number of nodes and can be configured within a single data center or across multiple sites.
- Data model. Cassandra is schema-optional, using a partitioned row store data model that is flexible. In this model, data is stored organized into rows based on a partition key—a subset of the primary key or the primary key itself if it’s simple.
- Read and write paths. Cassandra supports fast write and read operations by employing a distributed commit log and memtable for write requests, and a distributed read operation across replicas for reads.
- Gossip protocol. Cassandra’s gossip protocol for internode communication allows nodes to discover and share information about the cluster’s state and network topology.
Apache Cassandra Query Language
The program has its own language, Cassandra query language (CQL). CQL is SQL-like and was designed specifically for interacting with Cassandra databases. Offering a familiar syntax for anyone used to working with SQL databases, CQL also delivers features that are uniquely tailored to Cassandra’s distributed architecture and data model.
Apache Cassandra uses CQL (Cassandra query language), a SQL-like language. CQL provides
Key features of CQL include support for standard CRUD operations (create, read operations, updates, deletions) with data in Cassandra tables and control over the consistency level for read and write operations.
Apache Cassandra Design Architectures
Apache Cassandra supports several design architectures that cater to different use cases and requirements:
- Single data center architecture. This deployment of Cassandra within a single data center is suitable when the application’s data storage and processing needs can be met within a single geographic location.
- Multiple data centers with replication. Cassandra is deployed and data is replicated across multiple data centers to ensure high availability, disaster recovery, and improved performance for users distributed across different geographic regions.
- Active-active data centers. Multiple data centers actively serve traffic and process requests simultaneously to achieve low latency and high availability where users are distributed globally.
- Multi-region deployment. Cassandra instances are deployed across multiple geographic regions, with data centers located in different countries or regions, enabling compliance and improved performance.
- Hybrid cloud deployments. Here, Cassandra architecture is deployed in a hybrid cloud environment, with some instances run on-premises.
- Data modeling architectures. Cassandra supports wide-row, skinny-row, and compound key data models for big data applications.
Does ScyllaDB Offer Solutions for Apache Cassandra Architecture?
ScyllaDB architecture, data format, and query language are all similar to that of Apache Cassandra. However, ScyllaDB omits Java and its expensive pauses for garbage collection. ScyllaDB also features a shared-nothing asynchronous architecture that scales linearly as you add more nodes.
These key differences mean that it’s simple to improve performance at scale with reduced administration, fewer nodes, and lower infrastructure cost. Migrating from Cassandra to ScyllaDB is typically seamless, and demands minimal code modifications.
Learn more about how ScyllaDB architecture might offer your deployment an advantage here.
