Database Replication FAQs
What is Database Replication?
Distributed database replication involves copying data across multiple nodes so that a single node going down does not make the system unavailable and/or result in data loss.
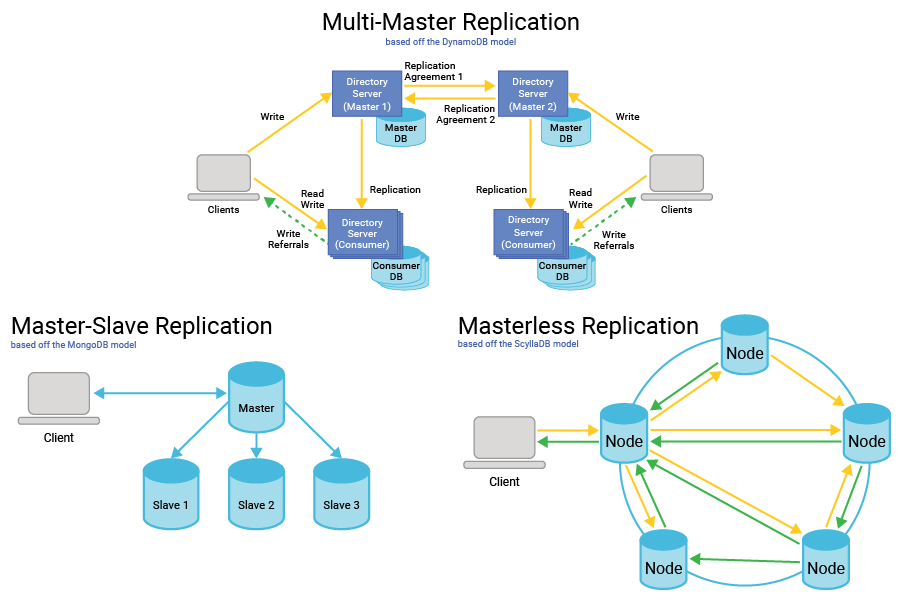
NoSQL databases tend to support data replication using three basic models: multi-master databases, such as DynamoDB, master-slave architectures, such as MongoDB, and masterless, such as ScyllaDB. Given their reliance on master nodes, both multimaster and master-slave architecture introduce a point of failure. When a master goes down, the process of electing a new master introduces a brief downtime. Even though the delay may be minimal, measured in milliseconds, that delay can still cause SLA violations.
A masterless architecture addresses this limitation. In these databases, data is replicated across multiple nodes, all of which are equal. In a masterless architecture, no single node can bring down an entire cluster. A typical masterless topology involves three or more replicas for each dataset. Adopting a NoSQL database that implements a masterless architecture provides yet another layer of resilience for high-volume, low-latency applications.
Database Replication Methods
There are two ways to time data transfer in the data replication process: asynchronous and synchronous replication.
Asynchronous replication in NoSQL databases sees the client send the data to the model server where the replicas take the data. The model server pings the client to confirm receipt of the data and copies it to the replicas. Asynchronous database replication offers greater ease of use and flexibility, but added risk of unknown data loss.
Synchronous replication copies data to the model server from the client server and then replicates it to all the replica servers before notifying the client. This is more time-consuming for verification and more rigid, but it is more likely to successfully copy all data before proceeding.
Types of database replication can also be classified based on server architecture. Single-leader architecture is loosely analogous to a somewhat inflexible version of synchronous data replication. Multi-leader architecture and no-leader architecture are more akin to distributed versions with multiple servers and asynchronous database replication.
SQL database replication can be described as transactional, snapshot, and merge replication.
Transactional replication. In this case, the DDBMS replicates transactions or changes to the original database in a sequence in real-time and users experience these changes on the replicated database almost instantly. Transactional replication guarantees transactional consistency and is typically used in server-to-server environments.
Snapshot replication. The DDBMS captures and overwrites a snapshot of data from the original database on the receiving database using the same server. Snapshot replication does not monitor for data updates and distributes data exactly as it appears at that moment in time. Snapshot replication is a bit slower than transactional replication and is typically used when data changes happen infrequently.
Merge replication. The most complex type of replication, this use case sees the DDBMS merge the data from multiple databases into a single receiving database. Merge replication allows independent changes by both publisher and subscriber and allows one publisher to send changes to multiple subscribers. Merge replication is often used in server-to-client environments.
Full replication, partial replication, and no replication schemes are all possible.
Full replication, in which every site stores the whole database, offers several advantages, including high availability of data, improved performance from local data retrieval, and faster execution of queries. The disadvantages of full replication include a slower update process needed at different locations and concurrency being more difficult to achieve.
The advantage of partial replication, in which only frequently used database fragments are replicated, is that it determines how many copies of each piece of data to make based on how important that data is.
The advantage of no replication, which stores each fragment on only one site, is the ease of achieving concurrency and data recovery. The disadvantages include slower execution of queries and less easily available data.
How Does NoSQL Database Replication Work?
Non-relational databases support data replication natively following several basic models. However, most of these introduce a point of failure with a single primary database. For example, multi-primary databases, such as DynamoDB, and primary-secondary architectures, such as MongoDB both introduce this weakness. When the primary database fails, downtime and SLA violations are possible.
A structure with no primary database such as ScyllaBD, which replicates data across multiple nodes, addresses this limitation. This type of architecture, also seen in Cassandra database replication, provides multiple replicas for each dataset and ensures no single node can cause an entire cluster to fail.
Example of NoSQL Database Replication
In a database like Cassandra or ScyllaDB,dData is always replicated automatically. Read or write operations can occur to data stored on any of the replicated nodes.
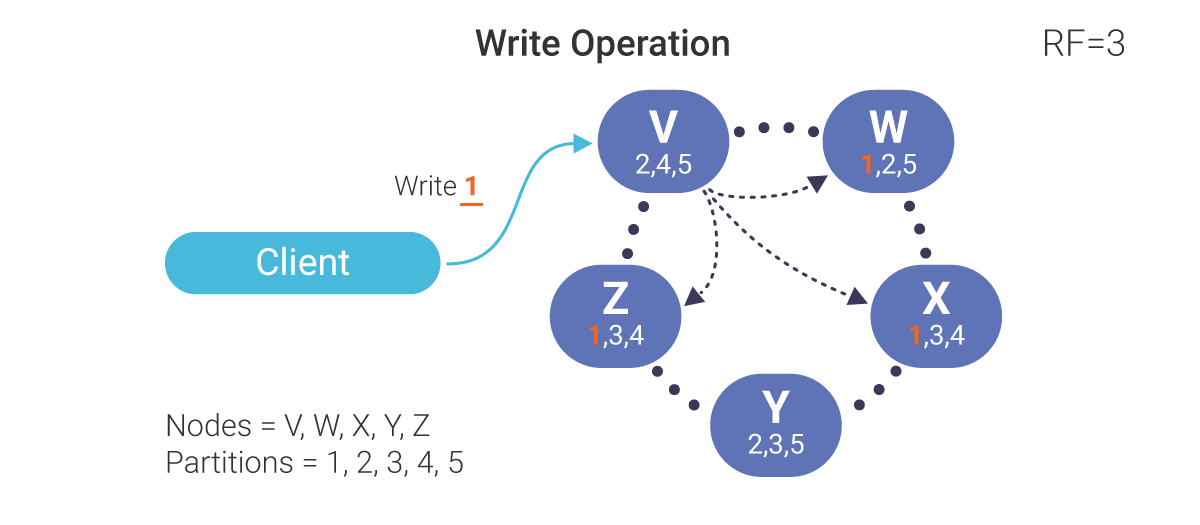
In the example above, our client sends a request to write partition 1 to node V; 1’s data is replicated to nodes W, X, and Z. We have a Replication Factor (RF) of 3. In this drawing, V is a coordinator node but not a replicator node. However, replicator nodes can also be coordinator nodes, and often are.
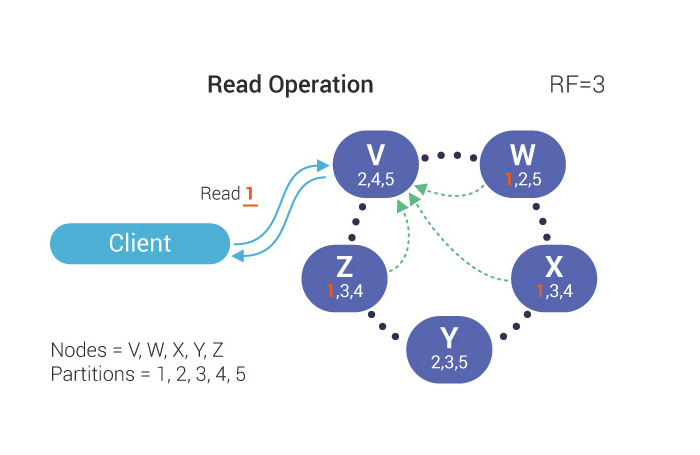
During a read operation, the client sends a request to the coordinator. Effectively because the RF=3, 3 nodes respond to the read request.
The Consistency Level (CL) determines how many replicas in a cluster must acknowledge read or write operations before it is considered successful.
Regardless of the Consistency Level, a write is always sent to all replicas, as set by the Replication Factor. Consistency Level control when a client acknowledges, not how many replicas are updated.
During a write operation, the coordinator communicates with the replicas (the number of which depends on the Replication Factor). The write is successful when the specified number of replicas confirm the write.
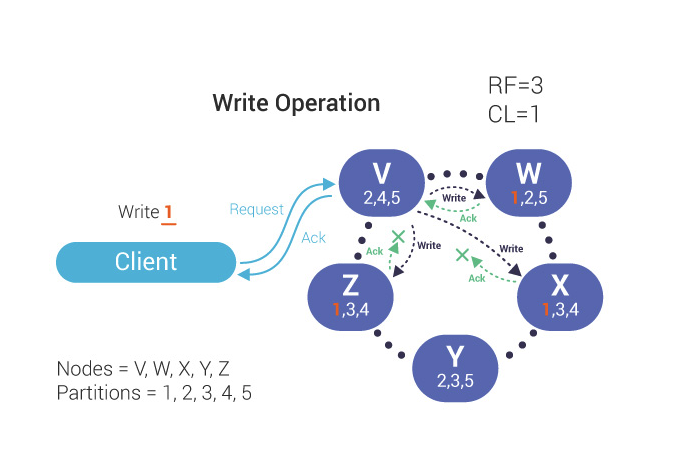
In the above diagram, the double arrows indicate the write operation request going into the coordinator from the client and the acknowledgment being returned. Since the Consistency Level is one, the coordinator, V, must only wait for the write to be sent to and responded by a single node in the cluster which is W.
Since RF=3, our partition 1 is also written to nodes X and Z, but the coordinator does not need to wait for a response from them to confirm a successful write operation. In practice, acknowledgments from nodes X and Z can arrive to the coordinator at a later time, after the coordinator acknowledges the client.
Database Replication Tools
Organizations typically use the database replication tool or built-in capability developed by the database software maker or invest in third-party database replication solutions or software to manage and execute database replication processes.
Various third-party database replication software platforms and other tools work with a range of popular databases:
- Informatica Data Replication targets a broad range of data warehouse appliances and databases to offer product series for integration, streaming, quality, and masking enterprise data.
- Quest SharePlex focuses mostly on on-premises and cloud solutions for Oracle database replication.
- Qlik Replicate software uses log-based capture of continuous data streams and automation to minimize IT operations workload and process big data efficiently.
Examples of tools for database replication from vendors include the following:
- IBM Db2 SQL replication tool has Q and SQL replication options for distributing source data to multiple targets, but not ideal for all uses due to high latency.
- Including SQL Server Integration Services (SSIS) for Azure database replication, Microsoft’s SQL integration features tools for cleaning, merging, aggregating, copying, extracting, and loading data.
- The Oracle GoldenGate tool offers simple configuration, visual management and monitoring, and log-based capture for Oracle databases.
Database Backup vs Replication
Database backup—sometimes called mirroring—and database replication are not the same. Database backup involves keeping a replicated copy of the primary database as a safety precaution in the event of failure. In contrast, database replication is not a mere backup plan but involves higher data availability and greater operational efficiency via an ongoing process.
Database Sharding vs Replication
Database sharding does not replicate data. Instead, it shards a single database into pieces and stores them on different systems. In contrast to database replication solutions, sharding alone cannot produce high availability.
Advantages of Database Replication
There are several advantages and disadvantages of data replication in distributed databases, including consistency tradeoffs between eventual and strong consistency. Data replication moves data securely and efficiently to improve the availability and performance of applications and databases.
The main advantage of using replication in a distributed database system is that if a node goes down, a higher replication factor means a higher probability that the data on the node exists on one of the remaining nodes. For example, if you have a RF of 3 and 2 nodes go down, one will still be available.
The most often cited database replication issues are related to the greater storage space required.
Does ScyllaDB Offer Options for Database Replication?
ScyllaDB delivers automatic multi-datacenter database data replication, which synchronizes clusters across geographical availability zones. Users set a replication factor (RF) and ScyllaDB stores multiple copies of the same data across the cluster on multiple nodes. This way, even if a node is lost, the user can still find the data which resides somewhere in the cluster.
In a multi-datacenter cluster, data is copied asynchronously among clusters according to how the keyspaces are defined. For example, with a replication DC1:3, data will only be stored in the first datacenter on three different nodes. Changing the replication factor to “DC1:3, DC2:3”, ScyllaDB will store three copies of the data in each datacenter. In ScyllaDB, multi-datacenter replication is rack-aware and datacenter-aware, ensuring that replicas are distributed both physically and geographically.
Learn more about multi-datacenter replication, and how ScyllaDB can help you achieve zero downtime here.
