Database Scalability FAQs
Relational vs NoSQL Database Scalability
Why are NoSQL databases more scalable?
Typically, NoSQL database scalability follows a horizontal scaling (scale out) approach, and this offers an advantage over relational database management systems (RDBMS) in many situations.
NoSQL databases are often considered more scalable than traditional SQL databases because they were designed with scalability in mind. NoSQL databases typically use a distributed architecture that allows them to scale horizontally across multiple servers or nodes, rather than relying on a single powerful server.
This distributed architecture of NoSQL databases allows them to handle large amounts of data and traffic by distributing the workload across multiple nodes. Furthermore, NoSQL databases often use a variety of techniques to improve performance and scalability, such as caching, replication, sharding, and partitioning. These techniques can help ensure that data is processed efficiently and quickly, even as the volume of data and traffic increases.
Overall, although there is no one most scalable database, the distributed architecture and performance-enhancing techniques used by NoSQL databases make them well-suited for handling large-scale data and traffic and typically more scalable than traditional SQL databases.
Are all NoSQL databases scalable?
No, not all NoSQL databases are highly scalable, but many NoSQL databases are designed with scalability as a core feature.
NoSQL refers to a wide variety of database systems. While some NoSQL databases are designed for high scalability, others may prioritize other features such as ease of use, performance, or consistency over scalability.
Some scalable NoSQL databases use a distributed architecture to achieve high scalability and availability. These databases are often designed to be horizontally scalable, meaning that data is partitioned across multiple servers, and new servers can be added to the system to increase capacity as needed. Examples of horizontally scalable NoSQL databases include Apache Cassandra, ScyllaDB, Amazon DynamoDB, and Google Cloud Bigtable. Other NoSQL databases that provide high scalability are also designed to vertically scale. NoSQL databases with a close-to-the-hardware design take advantage of the underlying infrastructure in order to run massive workloads on smaller clusters of larger, denser nodes.
Other NoSQL databases are designed for specific use cases or data models, and may not be as scalable. For example, some document databases such as Couchbase or CouchDB are designed for ease of use and flexibility, and may not be as scalable as other NoSQL databases. Similarly, some graph databases such as Neo4j are optimized for high level graph processing and may not be as easily scalable as other NoSQL databases.
Are relational databases scalable?
Relational databases can be more difficult to scale as the size and complexity of the data increases. This is generally due to their centralized architecture. They typically take a vertical approach to scaling. Vertical scaling refers to increasing the power of a single server or cluster rather than adding multiple servers/clusters to add instances of the database and scale up.
All data is stored in a single server, which can create a bottleneck as the amount of data and the number of users accessing the database grows. This can lead to performance issues and limit the ability to scale the database.
In addition, relational databases have a higher level of transactional consistency, which can result in a lower throughput and less scalability, particularly when dealing with high transaction rates.
A newer option for scalable relational databases is known as Distributed SQL databases. These are relational databases that are typically built to scale horizontally. They attempt to combine the benefits of traditional SQL databases with the scalability of NoSQL databases. Examples of these scalable SQL databases include CockroachDB and Google Cloud Spanner, while YugabyteDB is an example of open-source distributed SQL.
There are also several techniques that can improve the scalability of relational databases, such as partitioning, indexing, caching, and load balancing. However, these techniques require careful planning and implementation, and may not be as effective as other solutions for large-scale data processing, such as NoSQL databases or distributed SQL databases.
What Are Some Good Resources on Database Scalability?
Here are some detailed resources on database scalability:
Overcoming Barriers of Scaling Your Database: Scaling distributed databases successfully today requires meeting a myriad of challenges, from physical distribution of your data across on-premises locations, public cloud vendors, geographies and political entities, to adopting technologies to overcome fundamental operational bottlenecks. In this video, experts have an informal chat about how to navigate both technical ecosystem and database architectural challenges.
Why Scaling Up Beats Scaling Out: In the world of data-intensive applications, scaling out the database is the norm. As a result, database deployments are often awash in clusters of small nodes, which bring with them many hidden costs. For example, scaling out usually comes at the cost of resource efficiency, since it can lead to low resource utilization. So why is scaling out so common? Scaled out deployment architectures are based on several assumptions that we’ll examine in this white paper. This white paper demonstrates that these assumptions prove unfounded for database infrastructure that is able to take advantage of the rich computing resources available on large nodes.
7 Gamechangers’ Strategies for Database Speed at Scale; Learn how leaders like Disney+ Hotstar, Expedia, and Fanatics are evolving their data architecture for speed at scale. Strategies covered in this white paper include: 1) How Disney+ Hotstar is ensuring seamless viewer experiences at scale 2) How Expedia is delivering faster geo-targeted recommendations with 30% cost savings 3) How Fanatics reduced shopping cart abandonment while also reducing database nodes, costs & admin hassle
Overcoming Database Scaling Challenges with a New Approach to NoSQL: Scaling distributed databases successfully today involves a myriad of challenges, from physical distribution of your data across on-premises locations, public cloud vendors, geographies and political entities, to adopting technologies to overcome fundamental operational bottlenecks. In this video, database experts have an informal chat about how to navigate both technical ecosystem and database architectural challenges. This video shares practical tips and lessons learned from a variety of real-world scenarios that involve databases such as ScyllaDB, PostgreSQL, Cassandra, Bigtable and DynamoDB.
Database Scalability Comparison: Approaches and Impacts to Scalability in Databases
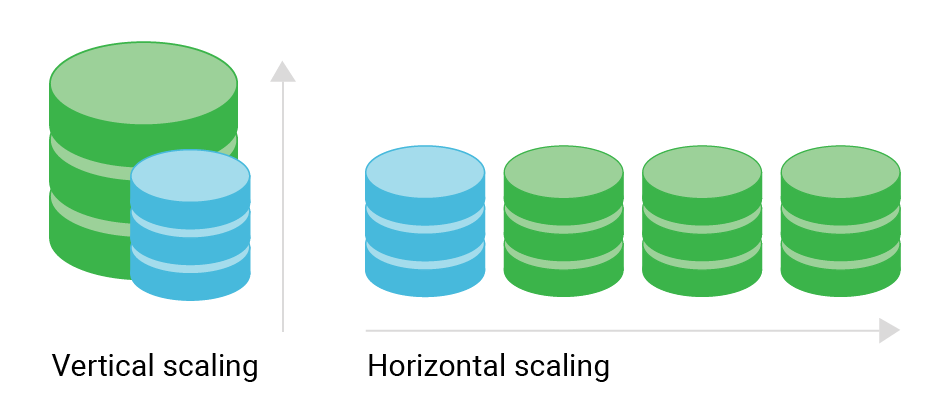
There are several database scalability techniques, including vertical scaling and horizontal scaling. Each database scaling technique has its own set of benefits and disadvantages:
Vertically scaled databases. This involves adding more resources to a single server, such as increasing the CPU, RAM, or storage capacity. This approach to scalability of databases is limited by the maximum capacity of the hardware and may result in a single point of failure.
Horizontal scaling. Horizontal database scaling involves adding more servers to a database system, distributing the load across multiple servers. This approach provides better scalability, database resilience, and fault tolerance as it reduces the risk of a single point of failure.
Additionally, the following are commonly associated with database scalability:
Caching. This involves using a caching layer to store frequently accessed data in memory, reducing the number of database read and write queries that go to the disk. This approach can improve performance and scalability.
Replication. This involves creating multiple copies of the database on different servers, such that updates made on one server are replicated to the others. Replication can improve the performance and fault tolerance of the system.
Load balancing. Distributing incoming requests across multiple servers helps to handle database load and avoid overloading any one server. Load balancing can improve scalability and availability.
Different types of databases use different approaches to scaling depending on their architecture, data model, and the specific needs of the application.
Relational/SQL databases. As explained above, relational databases are often less scalable, but they can still be scaled horizontally by partitioning the data, replicating the database, and using caching and load balancing.
NoSQL databases. Typically, NoSQL databases are horizontally scalable. This approach involves database replication by adding multiple servers to the system. NoSQL databases are designed with distributed, scalable database architecture for high availability and lower cost of scaling. Some examples of horizontally scalable NoSQL databases include Apache Cassandra, ScyllaDB, and Amazon DynamoDB. These databases use techniques like sharding, replication, and eventual consistency to enable scalability and fault tolerance.
Graph databases. Graph databases are designed to handle complex relationships between data entities and are used in applications such as social networks, recommendation engines, and fraud detection systems. These databases can be scaled horizontally by partitioning the data across multiple servers.
Time-series databases. Time-series databases are a good option for storing and analyzing time-stamped data, such as IoT sensor data or financial market data. These databases use techniques like data partitioning, clustering, and indexing to provide high scalability and performance.
When is it useful to use vertical scalability vs horizontal scalability?
If you have a database that is designed to take advantage of powerful hardware, it can help you run massive workloads on smaller clusters of larger, denser nodes. Here are some advantages of that approach:
Less Noisy Neighbors: On cloud platforms multi-tenancy is the norm. A cloud platform is, by definition, based on shared network bandwidth, I/O, memory, storage, and so on. As a result, a deployment of many small nodes is susceptible to the ‘noisy neighbor’ effect. This effect is experienced when one application or virtual machine consumes more than its fair share of available resources.
As nodes increase in size, fewer and fewer resources are shared among tenants. In fact, beyond a certain size your applications are likely to be the only tenant on the physical machines on which your system is deployed. This isolates your system from potential degradation and outages. Scaling up into large nodes shields your systems from noisy neighbors.
Fewer Failures: Since nodes large and small fail at roughly the same rate, large nodes deliver a higher mean time between failures,or “MTBF” than small nodes. Failures in the data layer require operator intervention, and restoring a large node requires the same amount of human effort as a small one. In a cluster of a thousand nodes, you’ll see failures every day. As a result, big clusters of horizontally scaled small nodes magnify administrative costs.
Datacenter Density: Many organizations with on-premises datacenters are seeking to increase density by consolidating servers into fewer, larger boxes with more computing resources per server. Small clusters of large vertically scaled nodes help this process by efficiently consuming denser resources, in turn decreasing energy and operating costs.
Operational Simplicity: Big clusters of horizontally scaled small instances demand more attention, and generate more alerts, than small clusters of vertically scaled large instances. All of those small nodes multiply the effort of real-time monitoring and periodic maintenance, such as rolling upgrades.
Does ScyllaDB Offer Solutions for Database Scalability?
Yes, ScyllaDB is a NoSQL database that’s purpose-built for data-intensive apps which require high throughput and predictable low latency. It provides powerful performance at massive scale – for a fraction of the cost of other solutions.
Uniquely architected to take full advantage of modern infrastructure, ScyllaDB harnesses processor, memory, network, and storage innovation to maximize performance and use less infrastructure. ScyllaDB delivers millions of operations per second with predictable single-digit P99 latencies, which translates to engaging experiences and competitive advantages.
