



MongoDB Cluster FAQs
What is a MongoDB Cluster?
MongoDB clusters are distributed environments of interconnected nodes. Each node stores data to ensure redundancy and distribute it across the cluster, reducing the risk of data loss and improving performance.
MongoDB Atlas clusters may be sharded to optimize horizontal scaling, or may instead be configured as replica sets for optimal data redundancy and failover protection.
Here are the basic difference between a sharded MongoDB cluster vs replica sets:
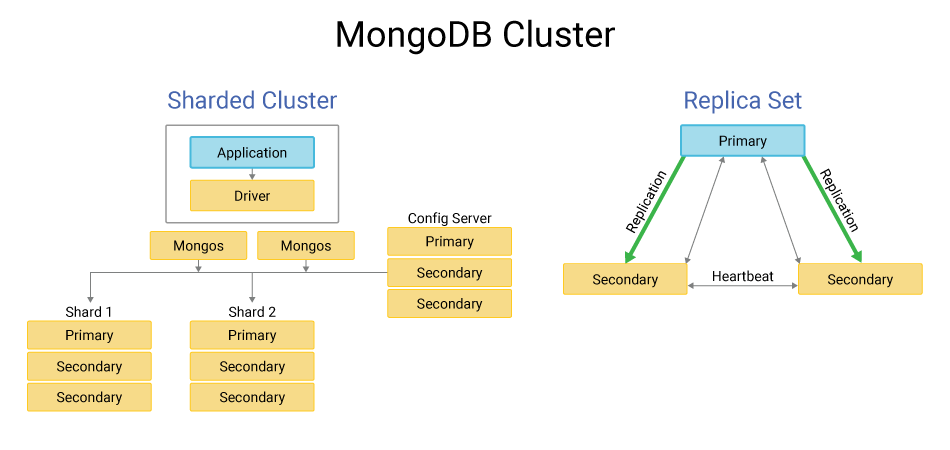
MongoDB replica set. In this group of MongoDB instances that maintain the same data set, a single primary node handles all client requests for data modifications and queries. The other, secondary nodes replicate that data set, offering data redundancy and high availability, and allowing for automatic failover in the event of a primary node failure.
MongoDB shard cluster. A sharded cluster in MongoDB consists of multiple replica sets, each set serving as a shard. Sharding involves horizontally partitioning data across multiple shards based on a shard key. This distributes data across multiple nodes to handle large volume and high throughput.
A MongoDB sharded cluster also includes query routers or mongos that route client requests to the appropriate shards based on the shard key. These clusters add multiple shards as data grows, providing improved performance and horizontal scalability.
Whether the replica set MongoDB cluster vs sharding cluster is the best structure depends mostly on the organization’s horizontal scaling requirements, availability demands, data access patterns, and resource constraints.
Both replica sets and sharded clusters can be deployed and managed as Kubernetes MongoDB clusters, although the approach may vary:
Replica sets are relatively straightforward to deploy as MongoDB Kubernetes clusters using StatefulSets or Stateful Applications (operators) to manage MongoDB instances as stateful pods. Kubernetes provides mechanisms for handling pod failures and ensuring data persistence, making it suitable for running replica sets.
Kubernetes MongoDB sharded clusters require more complex configurations due to the need to manage multiple replica sets and additional components such as query routers. The MongoDB Enterprise Kubernetes Operator or custom configurations can deploy and manage sharded MongoDB clusters in Kubernetes.
How a MongoDB Cluster Works
Data distribution. A MongoDB cluster distributes data across multiple interconnected nodes, each running an instance of MongoDB. The nodes can be organized into different roles: replica sets have primary, secondary, or arbiter nodes, while sharded clusters have config servers, query routers (mongos), and shards.
Scalability. Vertical scaling in MongoDB Atlas replica sets involves adding resources such as CPUs, RAM, or storage to individual nodes, while horizontal scaling involves adding more nodes to distribute the workload across servers. Sharded clusters support horizontal scaling by adding more shards as data volume grows, allowing for linear scalability.
Data consistency and replication. MongoDB Atlas replica sets use a primary-secondary model that acknowledges write operations only after being replicated to a majority of nodes. Sharded MongoDB clusters maintain consistency within each shard through replica sets and provide eventual consistency across shards with configurable consistency levels.
Failover and high availability. Replica sets have automatic failover mechanisms to ensure that a new primary node is elected if the current primary fails. Sharded clusters have query routers that automatically route requests around failed shards, and replica sets within each shard handle failover within the shard.
How to See Data in MongoDB Clusters
In a MongoDB cluster, users interact with the data primarily through the MongoDB query language and various MongoDB client tools:
Querying. MongoDB query language, which is JSON-based, is used to find data in clusters. Commands such as find, aggregate, insert, update, and delete allow users to retrieve, manipulate, and manage stored data.
MongoDB shell. This command-line interface allows users to interact directly with the MongoDB server. Users can run queries and administrative commands, view database and collection information, and perform various operations using the shell.
MongoDB Compass. This graphical user interface tool is used to visually explore data, run queries, create indexes, and perform administrative tasks.
Integrated apps. Applications that connect to the cluster using MongoDB drivers provide APIs for interacting with the database.
MongoDB aggregation framework. This allows users to filter, group, sort, and calculate aggregate values directly on data stored in clusters within the database.
Monitoring and management tools. Tools such as MongoDB Ops Manager, MongoDB Atlas, and third-party monitoring solutions allow administrators to monitor cluster performance, diagnose issues, and perform administrative tasks.
MongoDB Sharded Cluster Architecture
MongoDB cluster architecture is determined by whether the cluster is a replica set or a sharded cluster:
MongoDB replica set architecture
A replica set holds multiple MongoDB instances that each run on a separate server or container. Instances each play either a primary, secondary, or arbiter node role, as described in part above.
The primary node receives all write operations from clients and replicates these operations to secondary nodes. It’s responsible for processing write requests and handling read requests if read preference is set to “primary.”
Secondary nodes replicate data from the primary node asynchronously. They serve read requests if read preference is set to “secondary” or “nearest.”
An arbiter node participates in replica set elections but doesn’t store data. It breaks ties in the election process.
The oplog (operations log) records all write operations that modify replica set data. Secondary nodes use the oplog to replicate changes to the primary node.
MongoDB sharded cluster architecture
A sharded cluster consists of multiple replica sets, each acting as a shard. Shards store a portion of the data based on a shard key.
Config servers. These store metadata about the cluster’s data distribution, including the mapping between shard keys and shards. This metadata is used by query routers to route queries to the appropriate shards.
Query routers receive client requests, determine which shard contains the requested data based on the shard key, and route the query to the appropriate shard. They abstract the underlying sharding architecture from clients.
The balancer monitors data distribution and redistributes data across shards as needed.
The shard key is a field or fields in stored cluster documents that partitions data and is essential for evenly distributing data across shards and maximizing query performance.
Available MongoDB cluster sizes and tiers depend on whether the cluster is deployed using MongoDB Atlas, MongoDB’s fully managed cloud database service, or on-premises in a self-managed environment.
MongoDB cluster tiers are designed to provide different levels of performance, scalability, and features. The entry-level shared tier is suitable for development, testing, and small-scale applications and those want to get started with MongoDB.
Other tiers offer greater flexibility and scaling, including the higher-end Cluster Tierless option which is found in MongoDB Atlas Data Lake.
Deploying MongoDB on-premises or in a self-managed environment allows for more flexibility in configuring cluster sizes and hardware specifications based on specific infrastructure requirements. Users can deploy various MongoDB cluster types as standalone instances, replica sets, or sharded clusters, with each offering different levels of scalability and redundancy.
How to Create a Cluster in MongoDB
How to create clusters in MongoDB typically involves several steps, with some variation depending on whether you’re using MongoDB Atlas or deploying MongoDB clusters on-premises:
Create MongoDB clusters
Sign up for MongoDB Atlas or log in to your existing account. In the Atlas dashboard, navigate to the “Clusters” section and click the build MongoDB cluster button.
Choose your preferred cloud provider and the region where you want to deploy your MongoDB cluster setup. Select the appropriate cluster tier based on performance and scalability requirements.
Configure additional settings such as cluster name, MongoDB version, disk size, backup options, network settings, and other advanced options. Review your configuration settings before clicking the MongoDB create cluster button to deploy.
Monitor deployment progress in the Atlas dashboard.
On-premises or self-managed
Install MongoDB on the servers or virtual machines (VMs) where you want to build MongoDB clusters and deploy them. Configure the MongoDB deployment as a replica set or a sharded cluster based on the planned requirements.
Next, configure the settings for each replica set member or shard, including hostnames, ports, data directories, replication settings, authentication settings, and other configuration options. Start MongoDB instances on each server or VM based on the configured settings. Ensure the instances are communicating with each other and forming the desired cluster topology.
After you create a MongoDB cluster, monitor its health and performance using monitoring tools, logs, and administrative commands. Adjust configuration settings as needed to optimize performance, ensure data consistency, and maintain high availability.
Configuration settings for MongoDB clusters control various aspects of behavior, performance, and security:
- Storage configuration settings: Storage engine options, disk allocation, journaling, and data directory locations.
- Replication configuration settings: Replica set members, replication protocols, preferences for read operations, and consistency levels.
- Sharding configuration settings: Shard key selection, chunk size, balancer behavior, and migration thresholds in sharded clusters.
- Security configuration settings: Authentication, authorization, encryption, auditing, and network security.
- Performance optimization settings: Indexing, caching, resource allocation, and concurrency controls.
- Monitoring and alert settings: Thresholds settings and diagnostic tools for troubleshooting and performance tuning.
How to Connect to MongoDB Clusters
Regardless of whether you’re using MongoDB Atlas, a self-managed deployment, or a cloud-based environment, there are several steps to connect to MongoDB clusters:
Obtain the connection URI/string or hostname of your MongoDB cluster to connect. This information is typically provided by the MongoDB service provider (such as MongoDB Atlas) or system administrator.
Configure network access to ensure that your client application or network has permission to access the MongoDB cluster. In MongoDB Atlas, specify IP address whitelists or use a VPC peering connection. Choose a supported authentication mechanism to use when connecting to the cluster.
Install the appropriate MongoDB drivers based on the programming language and environment. Handle connection errors and exceptions at the code level.
Test your connection to the MongoDB cluster with basic queries or commands to ensure that you can read and write data successfully.
How to Delete Cluster MongoDB
Deleting a MongoDB cluster depends on the deployment environment. On-premises deployments will vary substantially.
Using MongoDB Atlas, use the dashboard to select the cluster to delete, access the settings, and initiate the process by selecting “delete cluster,” “terminate cluster,” or the similar available option.
The system may ask for a reason for the deletion, and will make the user confirm the change. Wait until the deletion is finished to verify it.
How to Check MongoDB Cluster Status
Here are some common approaches to checking MongoDB cluster status:
MongoDB Atlas
Atlas dashboard. The dashboard overview of all clusters details their status (e.g., “running,” “paused,” “scaling,” “initializing”), health, and other relevant details such as connection string, version, and region.
Cluster overview. Click on the name of the cluster you want to check to access its detailed overview page for more detailed information about health, database operations, and performance metrics.
Self-managed or on-premises deployment
MongoDB shell. Connect to one of the nodes using the shell and run administrative commands to check cluster status. For example, the rs.status() command provides information about replica set configuration, members, their state, and any recent changes.
Database profiling and monitoring tools. Tools such as MongoDB Ops Manager, MongoDB Cloud Manager, or third-party solutions can monitor the health and performance of clusters in real-time. They also provide alerts and performance metrics to track cluster status and identify bottlenecks.
System logs. These record error messages, warnings, and informational messages related to cluster status and typically contain valuable information about MongoDB processes, replication status, connectivity issues, and other relevant events.
Administrative commands. Commands such as mongostat, mongotop, db.serverStatus(), or db.stats() gather information about cluster status, performance, and resource utilization and provide real-time metrics about database operations, connections, and storage usage.
How to Make Clusters in MongoDB Perform Optimally
Assessing MongoDB cluster performance involves monitoring and optimizing various aspects of cluster configuration and application architecture. Here are some key steps and considerations for assessing and improving performance and reducing the overall level of MongoDB cluster latency:
Use monitoring tools such as MongoDB Ops Manager, MongoDB Atlas, or third-party monitoring solutions to track latency metrics. Monitor both read and write latency to understand the overall performance of the cluster.
Analyze latency trends over time to identify patterns. Look for spikes or sustained high latency that may suggest bottlenecks or resource contention.
The workload characteristics of the application should determine the balance between read and write operations. MongoDB clusters are optimized for both, but the optimal configuration may vary depending on your application’s requirements.
Measure the throughput of read and write operations using tools like mongostat, mongotop, or database profiling. Monitor metrics such as read/write throughput, query execution times, and operation queues to assess performance.
Optimize network connectivity between client applications and MongoDB clusters to reduce latency. Consider using dedicated network connections, virtual private networks (VPNs), or direct peering connections to minimize network latency.
Locate MongoDB cluster regions and availability zones geographically near to application users if possible to reduce network latency and improve responsiveness.
Optimize query performance with appropriate indexes designed to reduce execution time and improve overall cluster performance. The MongoDB Aggregation Framework can increase efficiency of complex data processing and analysis.
Enable automatic failover mechanisms in replica sets in case of primary node failures. Monitor replica set elections and failover events to ensure that they occur within acceptable time frames.
What Is the Difference Between Cluster vs Database in MongoDB?
“Cluster” and “database” are different pieces of MongoDB architecture.
A database is a logical container for collections of documents similar to a traditional relational database management system (RDBMS). Each can contain multiple collections, and each collection can contain multiple documents.
MongoDB databases organize and manage related data sets. Applications typically interact with them to perform operations on collections and documents.
In contrast, a MongoDB cluster is a distributed computing environment created by a group of interconnected servers or nodes that work together to store and manage data.
MongoDB cluster vs Alternative Solutions
Here is a brief look at how MongoDB clusters compare to MySQL Clusters and Elasticsearch Clusters in terms of data models, scalability, querying capabilities, and use cases:
MySQL Cluster vs MongoDB
MongoDB is a NoSQL document database that stores data in flexible, JSON-like documents. Its flexible data model suits it for applications with evolving data requirements.
In contrast, MySQL is a relational database management system with structured tables and predefined schemas. MySQL clusters have distributed, shared-nothing architecture that suit them for high-availability applications that demand ACID compliance.
Scaling both types of MongoDB clusters is discussed above. MySQL Cluster provides shared-nothing architecture with data distribution and replication across multiple nodes for scalability and fault tolerance. However, scaling MySQL Cluster can be more complex compared to either type of MongoDB cluster.
MongoDB clusters use a powerful query language with rich functionality, including CRUD operations, aggregation framework, and secondary indexes. They support complex queries and real-time analytics.
MySQL uses SQL (Structured Query Language) for querying data. It supports joins, transactions, and complex queries.
MongoDB is ideal for real-time analytics, while MySQL Cluster is commonly used for financial applications. Both of these clusters are commonly used for e-commerce platforms, billing, and mobile applications.
MongoDB Cluster vs an Elasticsearch Cluster
Elasticsearch clusters, similar to MongoDB clusters, store data in flexible JSON documents. However, Elasticsearch is optimized for advanced text search, relevance scoring, keyword-based querying, and real-time analytics on large volumes of data.
Elasticsearch is highly distributed by nature, allowing for horizontal scaling across nodes. It is commonly used for log and event data analysis, full-text search, and real-time analytics in various applications.
Does ScyllaDB Offer Solutions for MongoDB Cluster?
ScyllaDB and MongoDB are two very different databases. Here is how you might use each, and why.
Head-to-head, ScyllaDB outperforms MongoDB clusters in 132 of 133 performance measurements including latency and scalability. This was true for read-update, read-heavy, and write-heavy workloads with data set sizes ranging from 250GB to 10TB.
Scaling writes is inherently simpler with ScyllaDB because all you need to do is add nodes. No clusters needed! In fact, even a small 3-node ScyllaDB cluster outperforms a large 18-node MongoDB cluster.
MongoDB favors flexibility over performance, and allows users to issue any type of query, including queries that cause suboptimal performance with your production workload. ScyllaDB favors consistent performance over complete versatility and will warn you before allowing you to proceed with that type of unfavorable operation.
In fact, ScyllaDB and MongoDB work together well. MongoDB is well-suited for applications such as real-time queries over unpredictable behavioral data, or web backends with REST APIs and potentially flexible schemas.
Compare this to ScyllaDB, which is ideal for mixed batch and real-time workloads, real-time latency-sensitive data pipelines, and web backends using the strict GraphQL schema. The result is a formidable NoSQL combination.
Learn more about MongoDB vs ScyllaDB benchmarking.