NoSQL Throughput FAQs
How is Throughput of NoSQL Databases Determined?
The throughput of a NoSQL database is determined by a combination of factors, including database architecture, hardware resources, network configuration, and application workload.
Some common metrics used to measure NoSQL database throughput include:
Requests per second (RPS) or Operations per second (OPS). This measures the number of data requests or operations that a database can handle per second. A higher RPS or OPS indicates better throughput.
Read and write throughput. This measures the ability of a database to handle read and write requests separately. Some databases may have better read throughput than write throughput, or vice versa, depending on the underlying data model and architecture. For example, LSM-tree based databases are optimized for write-heavy workloads.
To determine the throughput of a NoSQL database, users may perform benchmark tests using representative workloads that simulate application usage patterns. For example, a tool such as Yahoo! Cloud Serving Benchmark (YCSB) to run a mix of read and write operations against the database and measure the resulting RPS or OPS.
Actual throughput for a NoSQL database will also depend on its hardware resources and the network configuration. Factors such as CPU, memory, disk I/O, and network bandwidth can all affect database performance and throughput. Therefore, it’s critical to carefully consider the hardware and infrastructure requirements of a NoSQL database before deploying it in production.
Relational vs NoSQL Throughput
SQL and NoSQL databases have different performance characteristics, so it’s difficult to make a general comparison without considering specific use cases and workloads.
SQL databases are typically optimized for handling complex queries and transactions involving multiple tables and relationships. They use a structured data model and ACID transactions (guarantees of atomicity, consistency, isolation, durability) to ensure data consistency and reliability. SQL databases are generally well-suited for applications that require strict data consistency, such as financial or transactional systems.
In contrast, NoSQL databases are generally optimized for handling large volumes of unstructured data as well as semi-structured data with high availability and scalability. They support different types of data and workloads with a variety of data models, such as key-value or wide column, as well as graph-based data structures, and document-oriented databases. Many NoSQL databases are generally well-suited for applications that require high throughput (e.g., for real-time data-intensive applications).
In terms of high performance, NoSQL databases can often achieve higher throughput and faster query response times than SQL databases, particularly for large-scale data processing and analysis. This is because NoSQL databases are designed to scale horizontally across multiple nodes, making them better for storing and retrieving data at scale, while SQL databases typically scale vertically by adding more resources to a single node.
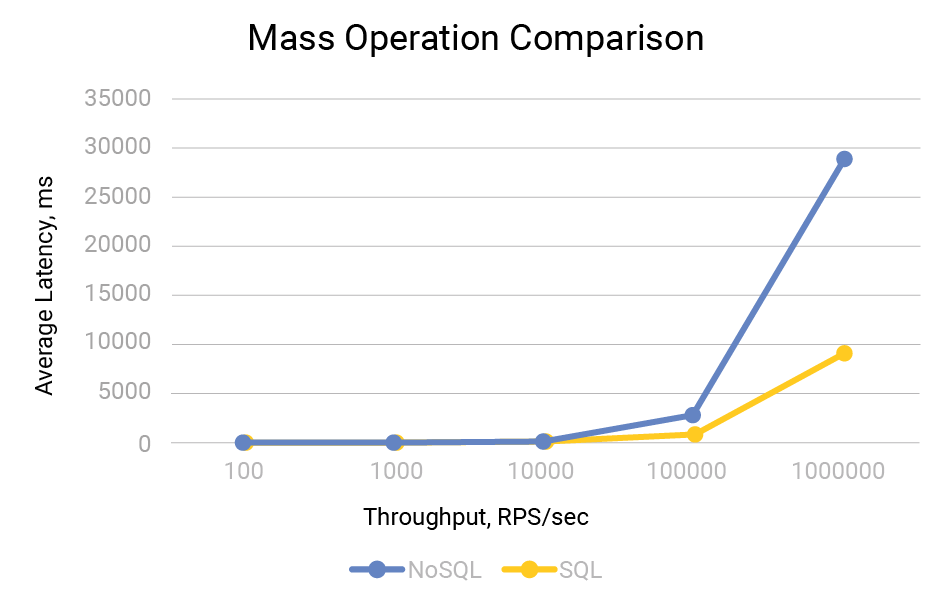
However, SQL databases can still provide excellent performance for specific use cases, particularly when data consistency and transactional integrity are critical. Some NoSQL databases also support ACID transactions, further confusing the distinction between SQL and NoSQL databases. [Benchmark: compare distributed SQL vs NoSQL database throughput]
What kind of use cases require high NoSQL database throughput?
Many use-cases require a high level of NoSQL database throughput (e.g. 1M OPS): for example, a busy ad bidding service, IoT data collection and analytics, real time chat. Today’s industries have needs that go beyond what traditional databases can offer – especially in cases where it’s more than what a single server can deliver. That’s why computing at that scale can only be achieved by a distributed database, especially ones that are focused on providing high throughput, low latency at scale.
Industry leaders are seeking ways of expanding and deepening the analysis of existing data – enriching decision making from analytics insights – then it’s easy to understand why use cases can easily reach or surpass the million of operations per second level.
Think of a streaming service’s use case of watch history. It can be used for different purposes: to display last watched programs that allows users to resume where they stopped, also to display a list of titles that are still in progress, and to enrich the user experience by using all that data to recommend relevant titles so the user keeps engaged on the platform. If the streaming service has dozens of millions of customers, it’s easy to see how that use case can surpass the million of operations per second mark – and it may even need more as it scales in the future. [Learn more about supporting 1M OPS database throughput]
How should you measure NoSQL throughput?
It is best to measure NoSQL database throughput in terms of peak operations per second. If you build and optimize with an average in mind, you’re likely won’t be able to service the upper ranges of that average. Focus on the peak throughput that you need to sustain to cover your core needs and business patterns – including surges. Realize that databases can often “boost” to sustain short bursts of exceptionally high load. To be safe, it’s best to plan for your likely peaks and reserve boosting for atypical situations.
How does NoSQL throughput compare to concurrency?
NoSQL database throughput is not the same as concurrency. Throughput is the speed at which the database can perform read or write operations; it’s measured in the number of read or write operations per second. Concurrency is the number of requests that the client sends to the database at the same time (which, in turn, will eventually translate to a given number of concurrent requests queuing at the database for execution). Concurrency is a hard number, not a rate over a period of time (like throughput). Not every request that is born at the same time will be able to be processed by the database at the same time. Your client could send 150K requests to the database, all at once. The database might blaze through all these concurrent requests if it’s running at 500K OPS. Or, it might take a while to process them if the database throughput tops out at 50K OPS.
What factors influence NoSQL throughput?
Many factors impact your throughput: the database architecture, data modeling, driver usage, infrastructure, cluster architecture, database internals, and so forth. It’s generally possible to increase throughput by increasing your cluster size (and/or power). But, you also want to pay special attention to concurrency. For the most part, high concurrency is essential for achieving impressive performance. But if the clients end up overwhelming the database with concurrency that it can’t handle, throughput will suffer, then latency will rise as a side effect. No system, distributed or not, supports unlimited concurrency.
How do NoSQL throughput tests compare to latency tests?
When performing a load test, you need to differentiate between a latency test and a throughput test. With a throughput test, you measure the maximum throughput by sending a new request as soon as the previous request completes. With a latency test, you pin the throughput at a fixed rate. In both cases, latency is measured.
Most engineers will start with a throughput test, but often a latency test is a better choice because the desired throughput is known e.g. 1M op/s. Especially if your production depends on meeting the needs of the SLA For example, the 99.99 percentile should have a latency less than 10ms.
Does ScyllaDB Offer Solutions for NoSQL Throughput?
Yes, ScyllaDB enables teams to achieve high throughput with predictable low latencies.
In a recent NoSQL benchmark, ScyllaDB stored a 1 PB data set using only 20 large machines running two side-by-side mixed workloads at 7.5 million operations per second throughput and single-digit millisecond latency. The results reflect a storage density of 50 TB/server, which is unparalleled in the industry. The amount of servers contributes to a low total cost of ownership (TCO) as well as operational simplicity.
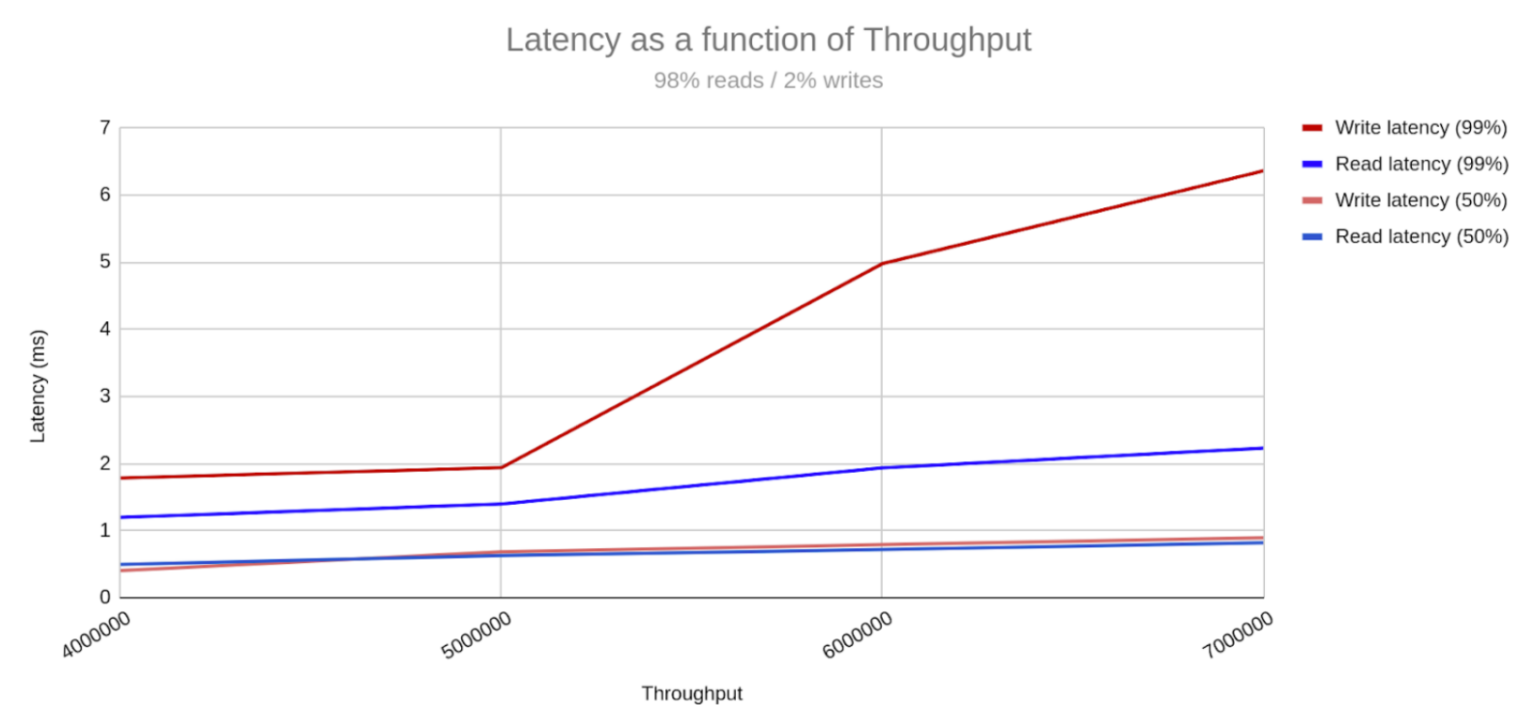
The ScyllaDB cluster achieved single-digit millisecond P99 latency with 7M TPS NoSQL throughput.
Learn more about how ScyllaDB’s throughput compares to other databases in these NoSQL benchmarks.
