Close-to-the-metal architecture handles millions of OPS with predictable single-digit millisecond latencies.
Learn More
Masterclass: Data Modeling for NoSQL Databases
Looking for extensive training on about data modeling for NoSQL Databases? Our expertsoffer a 3-hour masterclass that assists practitioners wanting to migrate from SQL to NoSQL or advance their understanding of NoSQL data modeling. This free, self-paced class covers techniques and best practices on NoSQL data modeling that will help you steer clear of mistakes that could inconvenience any engineering team.

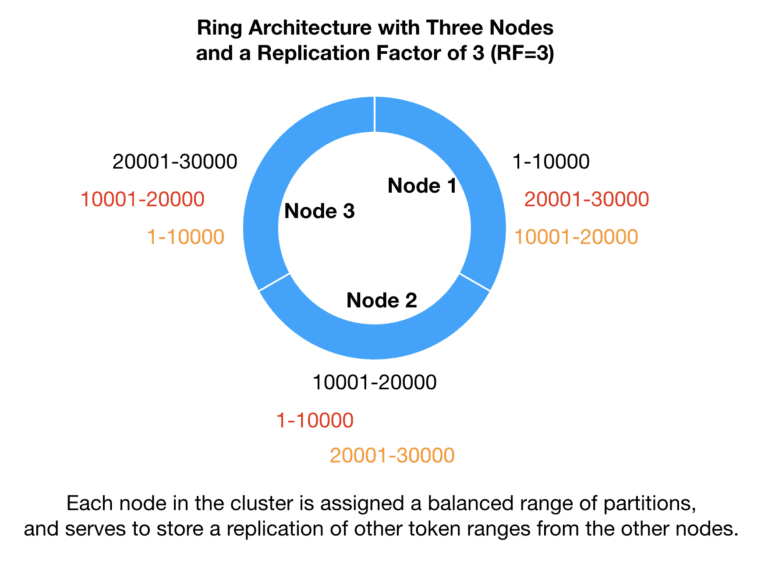
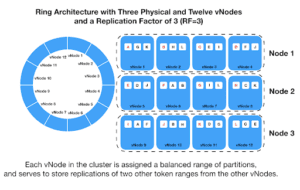
There are multiple steps in a Cassandra migration strategy for moving data to an eventually consistent database such as ScyllaDB, the fastest NoSQL Database, and verifying its consistency for a low latency, high volume application. If you are migrating from Cassandra to ScyllaDB, the steps look like this (at a high level):
- Duplicating the Apache Cassandra schema in ScyllaDB, although some variation is permissible
- Configuring the application/s to read only from Apache Cassandra while performing dual writes
- Taking a snapshot of all data to-be-migrated from existing clusters in Apache Cassandra
- Using the ScyllaDB sstableloader tool + Data validation to load SSTable files to ScyllaDB
- Conduct verification, with dual writes and reads, logging mismatches, until the system reaches the minimal data mismatch threshold
- Finally, in the last step the Apache Cassandra migration is complete, the Cassandra db reaches the end of its life, and only ScyllaDB reads and writes
Note that steps 2 and 5 are only required for live migration with no downtime and ongoing traffic.
There are several ways to handle failed Apache Cassandra schema migrations.
If sstableloader fails, it is necessary to repeat the loading job, because each loading job is per keyspace/table_name. Reloading the same data which was loaded in part before the failure, any duplication issues are eliminated by compactions.
If a node in the Apache Cassandra database fails, there are two possibilities. If the failed node was one you were using to load SSTables, you will also experience failure of the sstableloader. This will mean repeating the loading job, as explained above.
But if you were using RF>1, the data exists on another node or nodes. Simply redirect away from the failed node’s IP address and continue sstable loading from the other nodes, after which all the data should be on ScyllaDB.
If a ScyllaDB node fails and it was the target of sstables, again, the sstableloader will also fail. In that case, restart the loading job with a different target ScyllaDB node.
To rollback Cassandra DB migrations and start over again, run the following commands:
- Stop dual writes to ScyllaDB
- Use this command: [sudo systemctl stop scylla-server] to stop ScyllaDB service
- For all data already loaded to ScyllaDB, use [cqlsh] to perform [truncate]
- Restart dual writes to ScyllaDB
- Capture a new snapshot of all Cassandra nodes
- From the NEW snapshot folder, start loading SSTables to ScyllaDB again
To learn more about how the ScyllaDB architecture is architecturally different than Cassandra and why this matters, read this white paper: Building the Monstrously Fast and Scalable NoSQL Database: Eight Design Principles behind ScyllaDB
