Close-to-the-metal architecture handles millions of OPS with predictable single-digit millisecond latencies.
Learn More



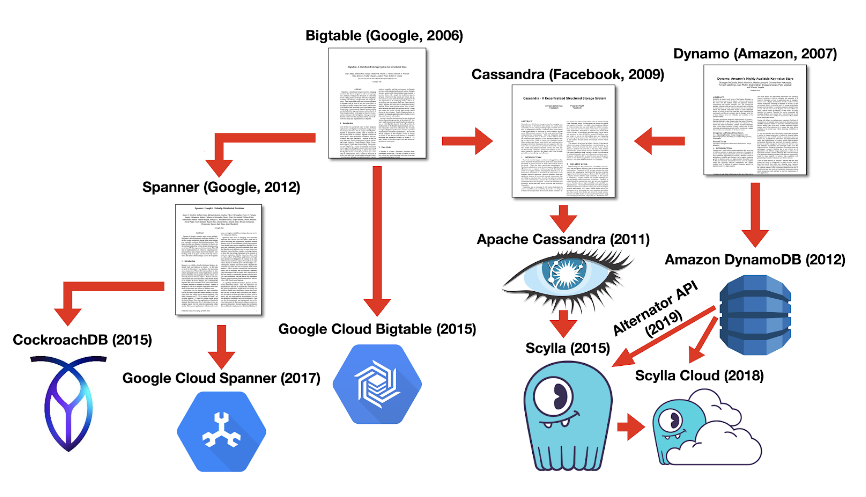
Types of NoSQL Databases
NoSQL Document Database
Document databases are known for being easy for developers to work with and offer teams a simple way to get started with a scalable and highly available distributed database. However, simplicity comes at the cost of performance, and performance degrades as data volume grows.
NoSQL document database design is simple and flexible. All data is stored as documents.
Document databases (also called document-oriented databases or document stores) store data in semi-structured document format using JSON, YAML, BSON, and XML. They support flexible schemas and allow developers to store and query data using the same model as their application code.
Common NoSQL Document Database use cases include:
- Catalogs
- User profiles
- Content management
Some examples of NoSQL Document databases are:
- MongoDB
- Couchbase
- CouchDB
- Realm
- Google Cloud Firestore
NoSQL Document Database Resources
NoSQL Graph Database
NoSQL graph databases use graph structures to represent connections between items as nodes, edges/relationships, and properties. They are used to identify and analyze hidden relationships between connected data.
In a graph database, a node record’s main purpose is to point to lists of relationships, labels and properties. Some graph databases store that data natively. This is called native graph storage. Others store that data in another NoSQL database. Wide column databases such as Cassandra, ScyllaDB, and Hbase are commonly used as graph database storage backends.
Beyond the core essentials of nodes, edges/relationships, and properties, common features of graph database in NoSQL include graph traversals, shortest paths, pattern matching, graph views, and support for popular graph query languages Apache TinkerPop Gremlin and W3C’s SPARQL.
Use cases for graph database in NoSQL include:
- Fraud detection and analytics
- Artificial intelligence and machine learning
- Social network analytics and management
- Recommendation engines
- Customer 360
Some examples of NoSQL graph databases are:
- Neo4J
- JanusGraph
- TigerGraph
- Dgraph
Graph Database Resources
Key Value NoSQL Database
A key-value NoSQL database associates named keys to values of any type, including complex types. A team using a key-value NoSQL database is typically looking for simplicity and speed. NoSQL key value database design is highly partitionable and optimized for reading and writing data. This enables key-value databases to achieve horizontal scaling that is impossible for many other types of databases.
Use cases for key-value NoSQL databases include:
- Shopping carts
- Session stores
- Blockchain
- Multimedia storage
Some examples of key-value databases are:
- Amazon DynamoDB
- Redis
- Memcached
- etcd
- ScyllaDB
- Riak KV
Key-Value Database Resources
In-Memory NoSQL Databases
In-memory NoSQL databases are a subset of key-value databases that are used for in-memory data caching. They generally deliver high performance and low latency by minimizing reads and writes to slower disk-based systems. However, this approach is not suitable for massive volumes of data since it requires data to fit in memory. Moreover, using in-memory databases introduces complexity since data is stored in multiple layers.
Some examples in in-memory databases are:
- Redis
- Memcached
- Amazon MemoryDB
In-memory Database Resources
Wide Column NoSQL Database
A wide-column NoSQL database organizes data storage into flexible columns that can be spread across multiple servers or database nodes. Multi-dimensional mapping is used to reference data by column, row, and timestamp. Wide column databases offer high-performance querying, scalability, and a flexible data model.
Use cases for wide column NoSQL databases include:
- Log data
- IoT (Internet of Things) sensor data
- Time-series data, such as temperature monitoring or financial trading data
- Attribute-based data, such as user preferences or equipment features
- Real-time analytics
Some examples of wide column databases are:
- Apache Cassandra
- ScyllaDB
- HBase
- Google BigTable
Wide Column Database Resources
NoSQL Search Engines
NoSQL search engine databases are focused on searching data content. They offer full-text search, complex search expressions, and ranking of search results. Indexes are used to categorize the similar characteristics among data and facilitate search capability.
Use cases for search engine NoSQL databases include:
- Text search
- Navigational search
- Logging and analysis
- Time-series data such as metrics and application events
Some examples of search engine databases are:
- Elasticsearch
- Splunk
- Solr
- Algolia
- Microsoft Azure Search
Search Database Resources
NoSQL Database vs SQL Database
Apache Cassandra NoSQL
Apache Cassandra is an open-source NoSQL database that runs on one or more physical or virtual computer servers known as a Cassandra cluster. Cassandra focuses natively upon two different NoSQL data models: it is primarily identified as a wide column store, but Cassandra also readily serves as a key-value store. Cassandra can support additional data models with extensions. For example, through the Linux Foundation’s JanusGraph Cassandra can serve as a graph database; it can also function either solo or supported by open source packages such as KairosDB a passable time series database (TSDB).
AWS NoSQL
There are six AWS NoSQL database models:
AWS key-value databases are part of Amazon DynamoDB. These enable users to store data in unique key-value pairs containing values for ID and any type, structure, or amount of data. This flexibility is ideal for the large volumes of data or requests found in eCommerce systems, gaming applications, and other high traffic applications.
AWS document database services include Amazon DocumentDB and DynamoDB. These are structured like key-value databases with values and keys stored in documents written in a markup language like XML, JSON, or YAML. This allows users to link documents to store data in hierarchies, such as for catalogs, user profiles, and content management.
The AWS wide column database offering is Amazon Keyspaces (for Apache Cassandra). These databases lack a strict column format and allow different data formats to be combined. Applications for wide column databases include fleet management, route optimization, and industrial maintenance applications.
Amazon Neptune is the AWS graph database offering, structuring databases as collections of nodes and edges. Nodes are the individual data values and the relationships between them are edges. These databases allow for organic tracking of intricately interconnected data, such as for social networking, recommendation engines, and fraud detection.
The AWS time series database service is Amazon Timestream. Amazon Timestream stores data in streams, sorted by time of ingestion, collection, or other metadata timestamp. This is useful for DevOps, industrial telemetry, and Internet of things (IoT) applications.
The AWS ledger database offering is Amazon Quantum Ledger Database (QLDB). OLDB is based on transparent, immutable logs that record and relate events to data values. Logs are cryptographically verified for data authenticity and integrity, making this a great choice for supply chains, banking systems, legal records, registrations, and other official systems of record.
ScyllaDB NoSQL
ScyllaDB is the database for data-intensive applications that require high performance and low latency. ScyllaDB is a wide-column NoSQL database fully compatible with Apache Cassandra and Amazon DynamoDB. It is API-compatible with both Apache Cassandra and DynamoDB and it can serve as the storage layer for graph databases like JanusGraph.
ScyllaDB’s NoSQL database is built with deep architectural advancements such as a highly asynchronous, shared-nothing, shard-per-core design that enable teams to harness the ever-increasing computing power of modern infrastructure — eliminating barriers to scale as data grows.
ScyllaDB is uniquely architected to capitalize on continuing hardware innovations. Modern infrastructure is fundamentally different than when NoSQL databases were first designed over a decade ago. Organizations now have access to servers with an increasing abundance of vCPUs, RAM, I/O, and fast NVMe storage. While legacy NoSQL databases are effectively insulated from the underlying hardware, ScyllaDB fully capitalizes on processor, memory, network, and storage innovation to maximize performance and use less infrastructure. Ultimately, this results in less admin and lower total cost of ownership. For instance, Comcast went from 962 Apache Cassandra nodes to only 78 ScyllaDB nodes. This efficiency results in anywhere from 2x to 10x cost savings over prior solutions.
Azure NoSQL
With Azure there are four NoSQL database options: key-value, columnar, document, and graph.
In Azure, key-value NoSQL databases are used for data caching, product recommendation, profile management, serving ads, session management, and user preferences. Cassandra via Cosmos DB managed service is one way to use a key-value database on Azure.
In Azure, columnar NoSQL databases are used for activity monitoring, messaging, personalization, recommendations, sensor data, social media analytics, telemetry, weather and other time-series data, and web analytics. Azure Table Storage offers a columnar database on Azure.
Within Azure, document databases are used for content management, inventory management, and product catalogs. MongoDB via Cosmos DB managed service is one way to use a document database on Azure.
Finally, in Azure, graph databases are used for fraud detection, organization charts, recommendation engines, and social graphs. Gremlin via Cosmos managed service is one way to use a graph database on Azure.
GCP NoSQL
Google’s Cloud Platform (GCP) offers these NoSQL database services:
- Cloud Firestore. Cloud Firestore is a document-oriented key-value store database. Cloud Firestore is easy to use with mobile applications and optimized for small documents.
- Cloud Datastore. This is a document database built for high performance, automatic scaling, and ease of use.
- Cloud Bigtable. Created as an alternative to HBase, Cloud Bigtable is a columnar database suitable for high throughput applications. Cloud Bigtable runs on HDFS.
- MongoDB Atlas. MongoDB Atlas is a managed MongoDB service built by the original makers of MongoDB and hosted by Google Cloud.
MongoDB NoSQL
MongoDB is an open-source NoSQL database, meaning it is based on a non-relational document model and is different from conventional relational databases such as MySQL, Oracle, or the Microsoft SQL Server at a fundamental level.
MongoDB and other NoSQL databases are useful for managing, storing, or retrieving large sets of distributed data and document-oriented information. MongoDB supports various forms of data, especially the kinds seen in big data applications and other processing. The MongoDB architecture is made up of documents and collections rather than rows and tables as in relational databases.
MongoDB is used for ad-hoc queries, aggregation, indexing, load balancing, server-side JavaScript execution and other tasks.
Datastax NoSQL
DataStax Astra DB is a serverless, NoSQL database-as-a-service (DBaaS) built on open-source Apache Cassandra to compete with MongoDB’s serverless, NoSQL DBaaS, Atlas. Astra DB is available across various cloud services platforms such as Amazon Web Services (AWS), Microsoft Azure, and the Google Cloud Platform (GCP) in multiple regions. Astra DB is a production-ready platform with automation for running operational Apache Cassandra tasks on Kubernetes such as backups, repairs, and monitoring.
Aerospike NoSQL Database
Aerospike Database is an open source, in-memory and flash memory distributed key-value NoSQL database management system. Aerospike is a good choice for a recommendation engine based on its core features: optimized Flash support sufficient for petabytes of data; large lists for recording behavior efficiently; aggregations and queries for real-time reporting; and strong support for Go, Python, and other languages.
Redis NoSQL
Redis is an in-memory, open source, key-value data store which can be used as a cache, NoSQL database, or message broker. Redis Enterprise is also a NoSQL database but includes added support and functionality for the enterprise level. Open source Redis and Redis Enterprise are entirely compatible.
Users can pair Redis with streaming solutions such as Amazon Kinesis and Apache Kafka as an in-memory data store to process, ingest, and analyze real-time data with latency of sub-milliseconds. Redis is a great option when real-time analytics are important, such as for ad targeting, IoT, personalization, and social media analytics.
Oracle NoSQL
Oracle NoSQL Database is a distributed, NoSQL key-value database created by Oracle Corporation. It offers horizontal scalability, data manipulation, and simple monitoring and administration. Oracle NoSQL Database is used for demanding applications and dynamic workloads that need low latency responses, elastic scaling, and flexible data models.
PostgreSQL NoSQL
PostgreSQL is an open source, enterprise-class relational database that supports both non-relational and relational querying through JSON and SQL, respectively. It is a highly resilient, stable database management system, and serves as the primary data warehouse or store for many geospatial, mobile, web, and analytics applications. PostgreSQL 12 is the latest major version.
PostgreSQL supports advanced data types and performance optimization across various commercial database counterparts, including SQL Server and Oracle. AWS supports PostgreSQL with Amazon Relational Database Service (RDS), a fully managed database service. PostgreSQL is used to build Amazon Aurora with PostgreSQL compatibility. And Postgres can bridge the gap between JSON and ANSI SQL, for example, by making the latter resemble the former. This functionality enables developers to start with unstructured data and adjust the balance between structured and unstructured data as the project progresses.
Firebase NoSQL
Google Firebase realtime database is a Google-backed application. This cloud-hosted NoSQL database lets developers create apps in Android, iOS, and online and sync, manage, and store data between users in real time. Firebase tools track analytics, repair and report app crashes, and create experiments with marketing and products. Cloud Firestore allows users to sync, store, and query app data at scale.
Firebase offers various features:
- Google Analytics for Firebase. Unlimited, free reporting on up to 500 separate events, user behavior analytics in iOS and Android apps.
- Firebase Authentication. For enhancing the sign-in and onboarding experience for users and building secure authentication systems, this feature offers a complete identity solution, supporting phone auth, email and password accounts, as well as Facebook, GitHub, Google, Twitter login, and other options.
- Firebase Cloud Messaging (FCM). A cross-platform messaging tool for receiving and delivering messages on Android, iOS, and the web reliably and free.
- Firebase Realtime Database. A cloud-hosted NoSQL database that stores and syncs data between users in real time, across all clients, so it is still available offline.
- Firebase Crashlytics. A real-time crash reporter that tracks, prioritizes and repairs stability problems.
- Firebase Performance Monitoring. This monitors performance characteristics and insights for iOS and Android apps.
- Firebase Test Lab. A cloud-based infrastructure for app-testing that allows developers to test theirAndroid or iOS apps across a variety of devices and configurations and see the results, including screenshots, videos, and logs, in the Firebase console.
Developers use Firebase to create onboarding flows, including fast, intuitive sign-in processes, customize “welcome back” screens for better UX, define audiences based on user behavior for content targeting, progressively roll out new features, and more.
Hadoop NoSQL
Rather than being a kind of database, Hadoop is a software ecosystem that enables massively parallel computing. This makes it a supporter of some types of NoSQL distributed databases that allow for massive distribution of data across many servers with little reduction in performance.
Python NoSQL
Python has a built-in database: SQLite. It is also commonly used with PostgreSQL and MySQL. However, Python can also interact with NoSQL databases such as MongoDB. Commonly, a Python user would create a simple SQLite database with the sqlalchemy library, or a MongoDB NoSQL database using pymongo.
Best NoSQL Databases for Analytics vs. the Best NoSQL Database for Transactions
In a typical database, there are numerous workloads running at the same time. Each workload type dictates a different acceptable level of latency and throughput. For example, consider the following two workloads:
OLTP (Online Transaction Processing), the backend database for your application, handles a high volume of requests. It requires fast processing and is latency sensitive.
OLAP (Online Analytical Processing ) performs data analytics in the background. It handles a high volume of data. However, slow queries are acceptable, so it is essentially latency agnostic.
Teams traditionally had to separate these database workloads, either to isolated clusters, isolated virtual data centers or time-based segregation (run analytics/reporting overnight). Each of these has associated limitations, risks and/or significant costs.
The analogy is to consider OLAP like freight trucks: large eighteen wheelers hauling a lot of data. The raw throughput — data volume — is what is important. OLTP, on the other hand, is more like a sports car. Built for data velocity, it is latency-sensitive. By using one best database for analytics and another for transactions, you are essentially building one data highway for trucks and another highway for sports cars. This approach is inherently inefficient. A better approach is to run all traffic on the same highway, and grant some lanes of traffic priority over others.
The best way to handle both analytical and transactional workloads in the same database is to use an approach called workload prioritization. Workload prioritization splits workloads into groups and prioritizes their resource distribution according to a user-defined ratio. This mechanism kicks in only when there is a conflict about a resource (for example, under extremely high loads).
NoSQL Database Comparison: Low Latency
In general, database latency is influenced by factors such as network latency, disk I/O, data size, throughput, workload characteristics, and how the database is built (database architecture and database internals). For a detailed look at the many factors that impact database latency, read the free book Database Performance at Scale.
Here is a quick look at specific databases considered for low-latency use cases.
Cassandra Latency
Cassandra’s distributed architecture aims to minimize latency by spreading data across nodes, enabling parallel processing of requests. However, latency can still vary based on factors like data distribution, consistency levels, and hardware performance. Monitoring and tuning configurations such as replication strategies and consistency levels can help optimize Cassandra’s latency performance.
For a specific example of Cassandra latency based on benchmarks, here is a look at Cassandra latency compared to ScyllaDB latency:
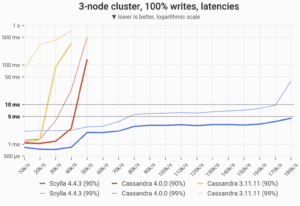
[Read more about this Cassandra latency benchmark]
DynamoDB Latency
DynamoDB achieves low latency through distributed data storage, “autoscaling”, and caching mechanisms. Optimizing table design can help minimize latency in DynamoDB.
For a specific example of DynamoDB latency based on benchmarks, here is a look at DynamoDB latency compared to ScyllaDB latency:
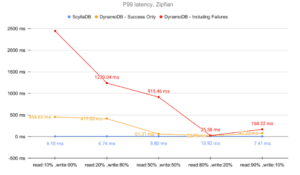
[Read more about this DynamoDB latency benchmark]
MongoDB Latency
MongoDB’s architecture allows for horizontal scaling, distributing data across multiple nodes to minimize latency. However, it is far from linearly scalable. Techniques such as indexing, sharding, and replica sets can be utilized to optimize MongoDB’s latency performance. Monitoring system metrics and adjusting configurations can help maintain low latency in MongoDB deployments.
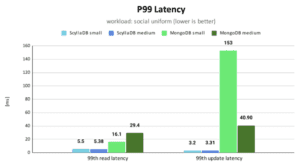
For a specific example of MongoDB latency based on benchmarkss, here is a look at MongoDB latency compared to ScyllaDB latency: