Close-to-the-metal architecture handles millions of OPS with predictable single-digit millisecond latencies.
Learn MoreMonster SCALE Summit 2025 — Watch 60+ Sessions Now
- Products
- Quick Links
Why ScyllaDB?
Is ScyllaDB right for me?
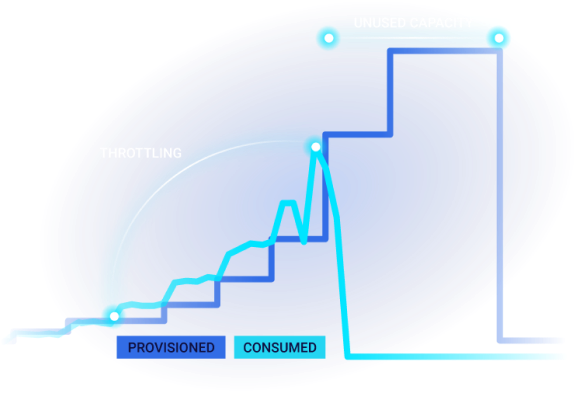
ScyllaDB is purpose-built for data-intensive apps that require high throughput & predictable low latency.
Learn More - Products
- Related Technologies
- Quick Links
- Developers
- Users
- Resources
- Featured Resource
ScyllaDB University
Level up your skills with our free NoSQL database courses.
Take a CourseScyllaDB Blog
Our blog keeps you up to date with recent news about the ScyllaDB NoSQL database and related technologies, success stories and developer how-tos.
Read the Blog - Resource Center
- Events
- Compare
- Featured Resource
- Pricing
- Contact Us
- Chat Now
- Get Started
- Sign In
- Search
- Button Links