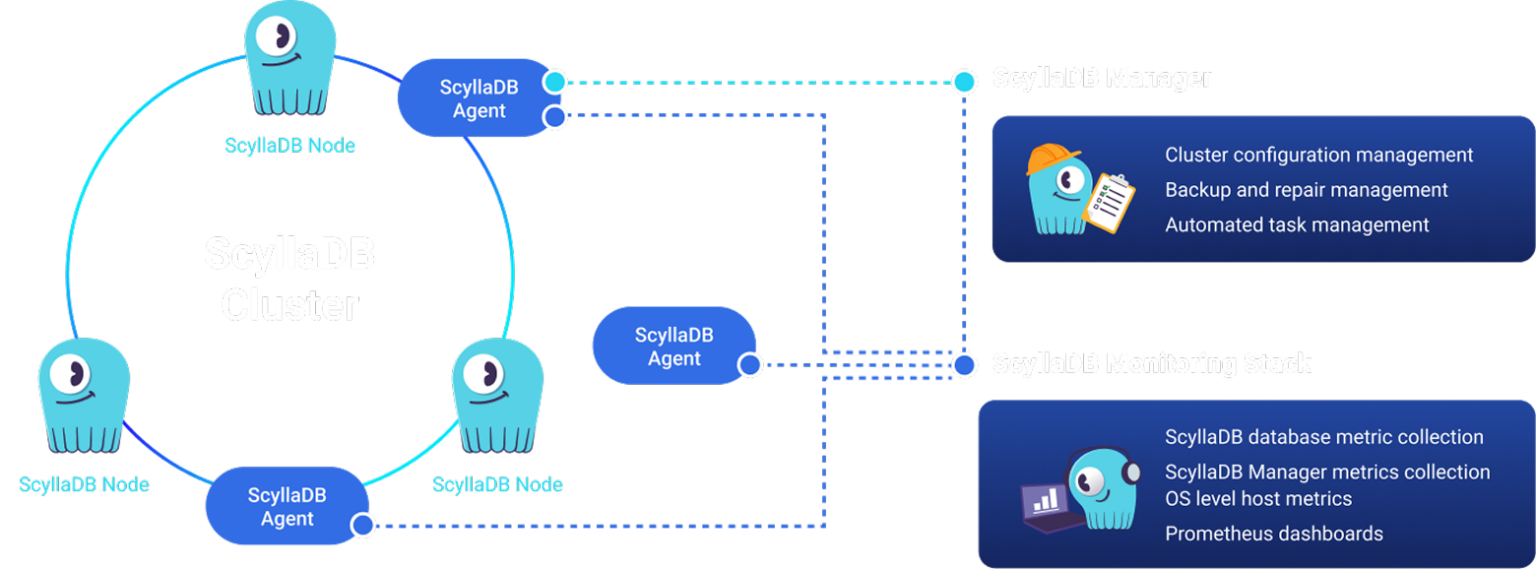
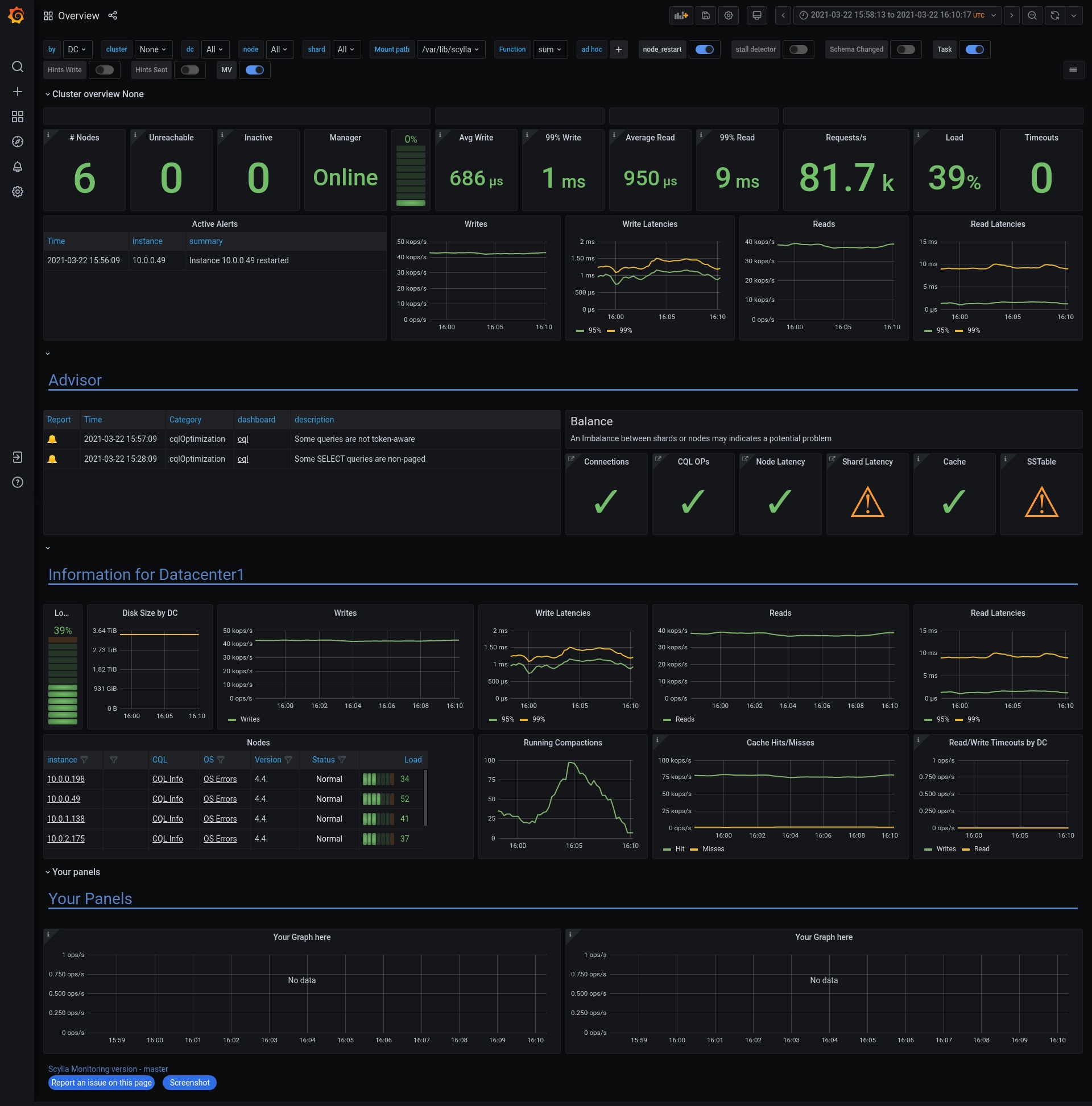
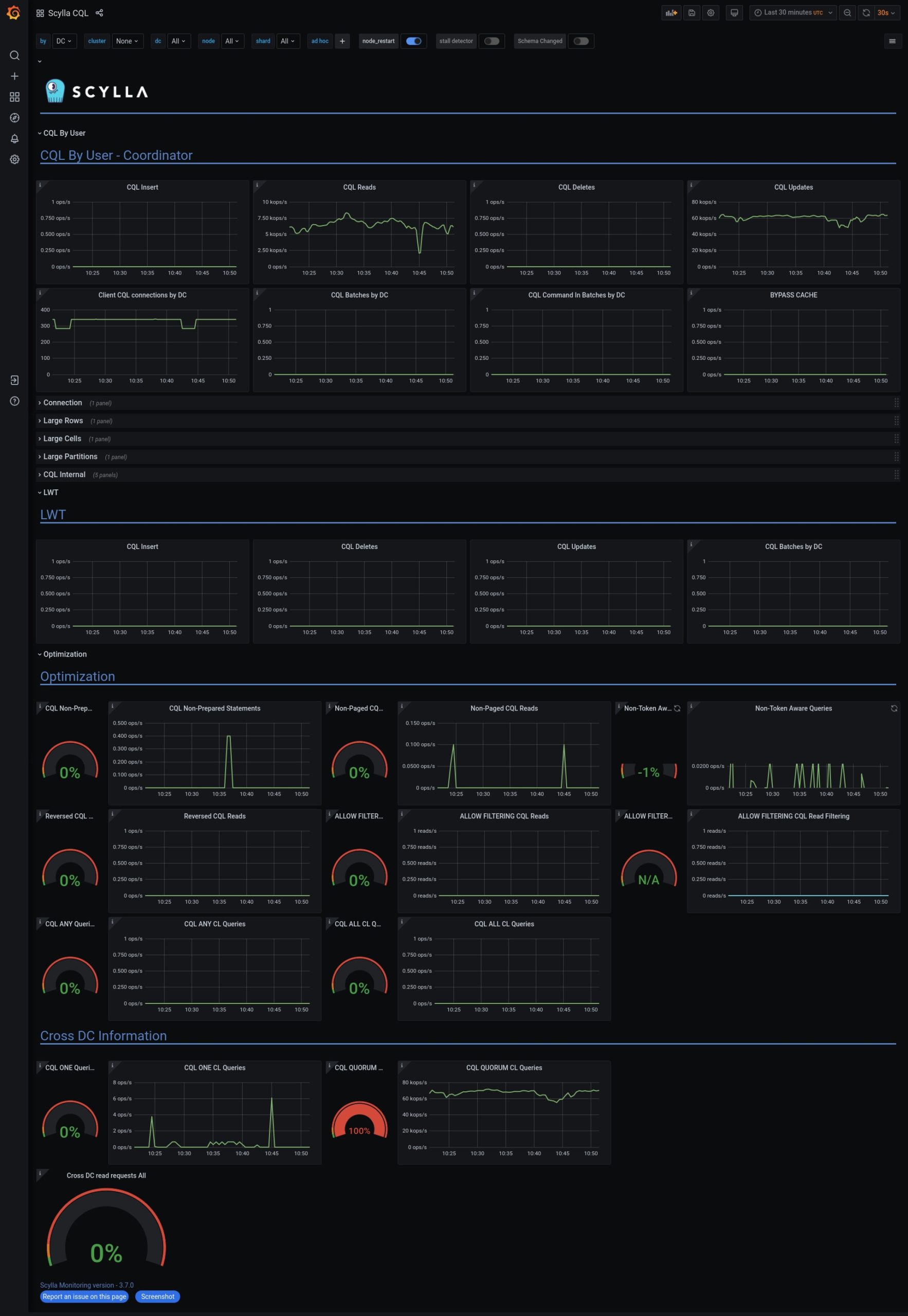
Close-to-the-metal architecture handles millions of OPS with predictable single-digit millisecond latencies.
Learn MoreScyllaDB Vector Search Early Access. Powering real-time AI, recommendations, and RAG at scale. Learn more
- Products
- Developers
- Users
- Resources
- Featured Resource
ScyllaDB University
Level up your skills with our free NoSQL database courses.
Take a CourseScyllaDB Blog
Our blog keeps you up to date with recent news about the ScyllaDB NoSQL database and related technologies, success stories and developer how-tos.
Read the Blog - Resource Center
- Events
- Compare
- Featured Resource
- Pricing
- Contact Us
- Contact Us
- Get Started
- Sign In
- Search
- Button Links