
Close-to-the-metal architecture handles millions of OPS with predictable single-digit millisecond latencies.
Learn MoreMonster SCALE Summit 2025 — Watch 60+ Sessions Now
Close-to-the-metal architecture handles millions of OPS with predictable single-digit millisecond latencies.
Learn MoreScyllaDB is purpose-built for data-intensive apps that require high throughput & predictable low latency.
Learn MoreLevel up your skills with our free NoSQL database courses.
Take a CourseOur blog keeps you up to date with recent news about the ScyllaDB NoSQL database and related technologies, success stories and developer how-tos.
Read More ScyllaDB uses eventual consistency to optimize performance and availability for database tables. However, there is little need to apply this to metadata for topology (nodes, data distribution) or schema (table format) information. This type of information doesn’t change frequently, isn’t commutative, and must be replicated everywhere. Raft consensus algorithms deliver strong consistency, starting with ScyllaDB 5.4 and, by default, with ScyllaDB 6.0. They are used to safely and quickly replicate topology, schema data, and many management subsystems within ScyllaDB.
Immediate and strong consistency with Raft allows for rapid and concurrent bootstrapping of multiple nodes in parallel. A centralized, highly available (HA) topology coordinator runs alongside the Raft leader to perform linearizable reads and writes of topology changes. Each node has a coordinator in shard 0 and forms a group with a lead coordinator for the overall cluster. If the leader fails, automatic coordinator failover occurs, and a new leader is elected.
Every topology operation registers itself in a queue called topology requests, and the coordinator works off this queue, providing an illusion of concurrency while preserving operational safety. Before Raft, information about the cluster members was propagated through gossip. Now, the state is propagated through Raft and consistently replicated to all nodes. A snapshot of this data is always available locally so that starting nodes can quickly obtain the topology information without reaching out to the majority of the cluster. The result is node operations run in a few seconds instead of tens of seconds.
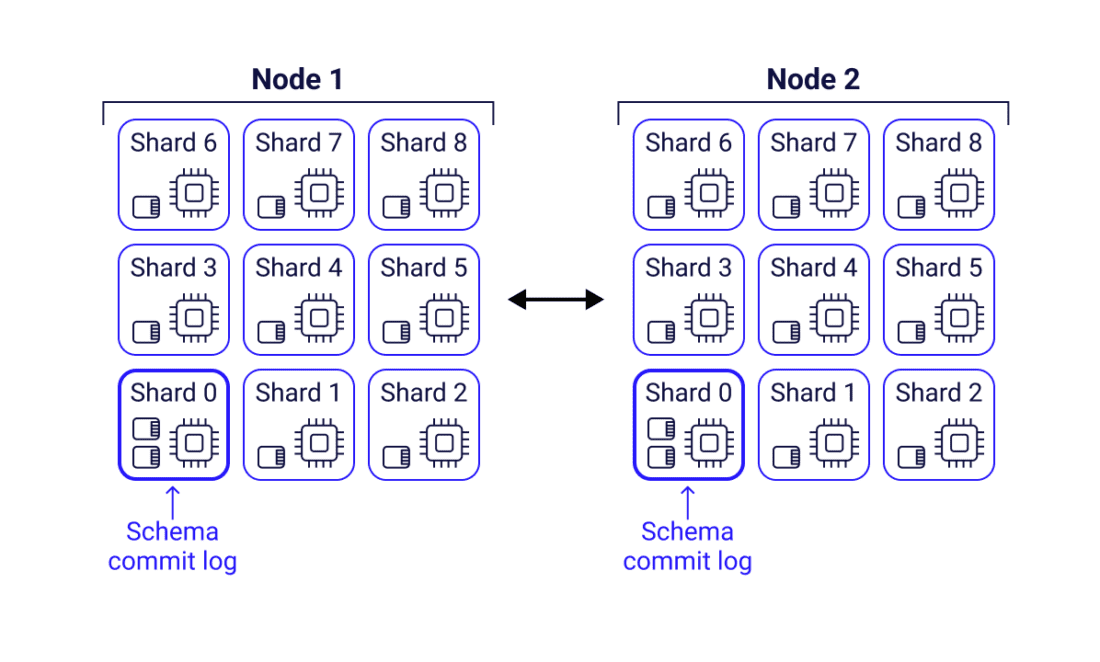
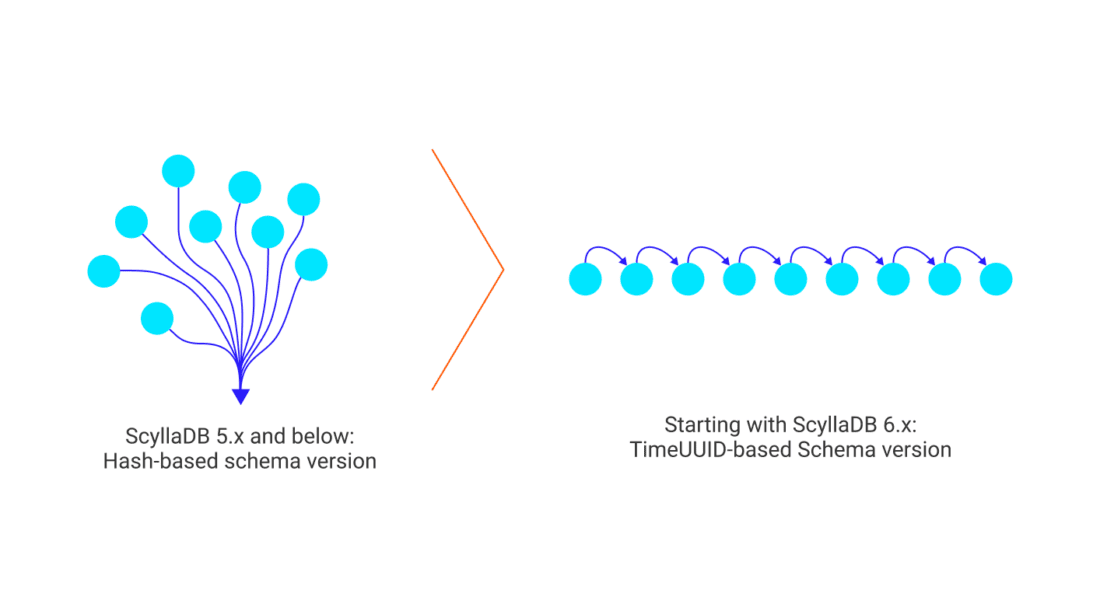
The Raft protocol now plays a crucial role in managing database schema changes. Operations such as CREATE, ALTER, or DROP for KEYSPACE, TABLE, INDEX, UDT, MV, and more are now handled by Raft, ensuring the safe and concurrent application of these changes. Once Raft is enabled, the Raft consensus algorithm serializes all schema management operations, preventing conflicts or data loss. With Raft, schema changes are propagated quickly as the cluster leader actively pushes them to the nodes, using a TimeUUID-based schema version instead of a Hash-based approach. In a healthy cluster, nodes can learn about the new schema in just a few milliseconds, significantly improving from the previous time of ten to twenty seconds per schema change.
The introduction of Tablets in ScyllaDB 6.0 has brought significant improvements over the previous vNodes approach. vNodes, defined only during bootstrap, posed limitations in scaling and data streaming due to their serial nature. In contrast, Tablets offer a more dynamic and granular approach to node partitioning within keyspaces. Bootstrapping a node with Tablets typically takes only a minute, after which the new node is ready to receive data. Most notably, this bootstrapping can be performed on dozens of nodes in parallel. Further, the time to double a 3-node cluster is reduced from two hours to 30 minutes. The larger the number of nodes in a cluster, the greater the time savings. For instance, a 60-node cluster can be doubled in capacity in 6 hours with Tablets versus 120 hours with vNodes. Unlike with vNodes, you can bootstrap new nodes while, in parallel, decommissioning other nodes.
The built-in load balancer manages all cluster node bootstrapping, decommissioning, expansion, and contraction operations. It detects any imbalance and starts moving Tablets from overloaded nodes to the new node. All Tablets are the same size, 5 GBytes, and become operational in 2 minutes, relieving the load on the original servers. If a node is decommissioned, the load balancer performs the reverse operation, evacuating nodes and moving their tablets to other active nodes.
Tablets maintain the same shard-per-core mapping as vNodes and are equal in size. However, unlike vNodes, the location (all vNodes were allocated across all shards based on the token ring), and total count of Tablets within a node can change to further optimize CPU and storage usage.
In a keyspace, each table is divided into Tablets of equal size, with smaller tables having a smaller number of tablets. Small tables with little data may end there. Compared to token partitioning in vNodes, this optimization avoids small table fragmentation and makes scans more efficient.
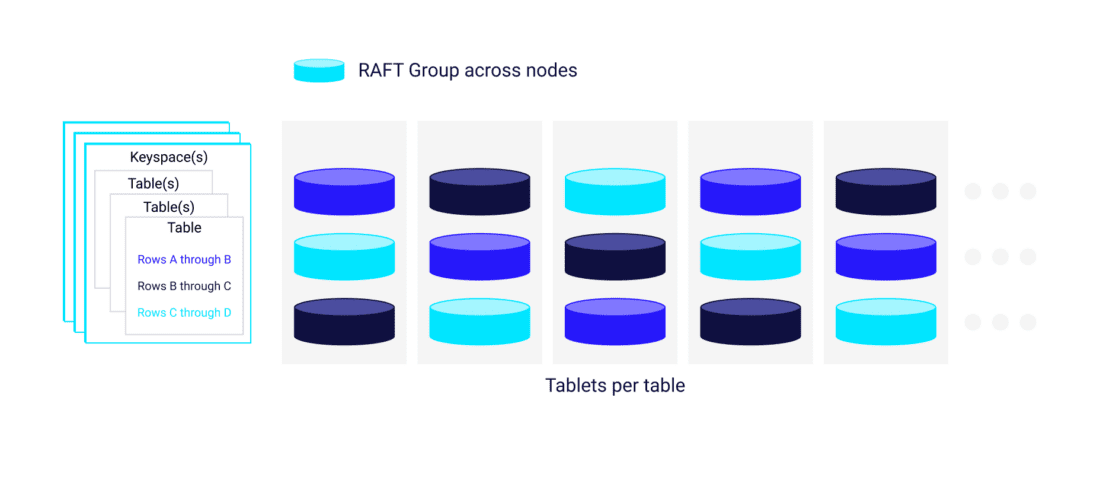
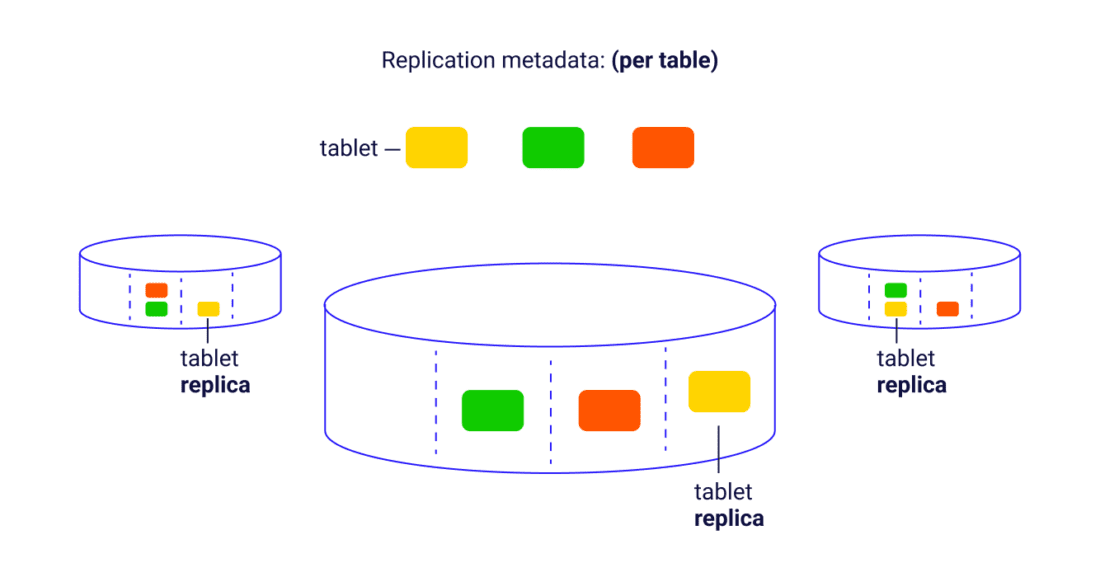
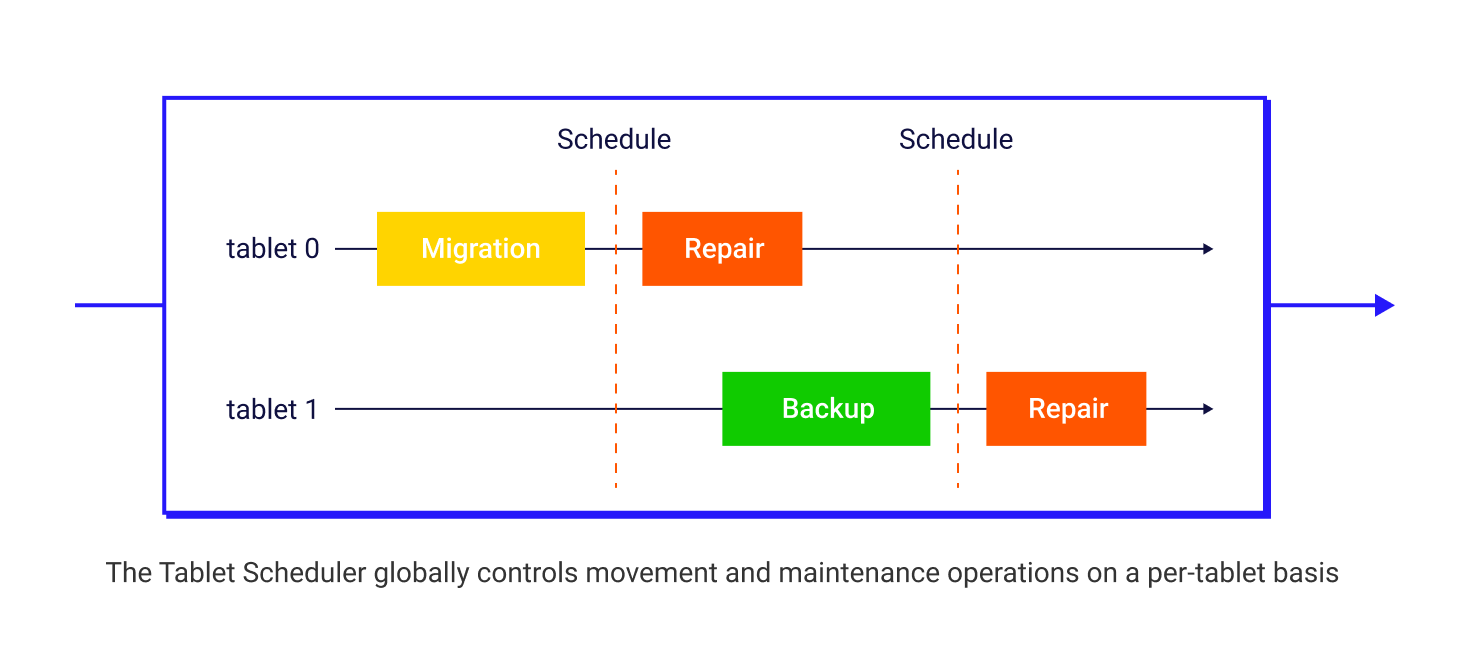
Replication and state management for the tablets across multiple nodes (how many Tablets for each table, token boundaries for each Tablet, which nodes, what kind of transition the tablet is undergoing, and so forth) is handled by Raft consensus metadata as a Raft group. A Tablet scheduler globally controls movement and maintenance operations on a per-Tablet basis. There is a Tablets table that stores all Tablet metadata and serves as a single source of truth for the cluster as its topology evolves (topology state, number of tablets per table, the token boundaries for each tablet, and which nodes and shards have which replicas).
Note that all existing drivers will work with both vNodes and Tablets. However, new tablet-aware drivers for all five programming languages provide improved performance and lower latency. Drivers start out without knowledge of where tokens are located but learn over time, directly requesting from the correct node, reducing lookup speeds for subsequent queries.
Because Tablets and vNodes shard at the Keyspace level, ScyllaDB allows for co-habitation of vNodes and Tablets on a per-Keyspace basis within a node.
Apache® and Apache Cassandra® are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. Amazon DynamoDB® and Dynamo Accelerator® are trademarks of Amazon.com, Inc. No endorsements by The Apache Software Foundation or Amazon.com, Inc. are implied by the use of these marks.

